|
DOI: 10.25136/2409-8647.2019.4.27580
Received:
03-10-2018
Published:
06-01-2020
Abstract:
Ubiquitous implementation of the modern technologies of digital economy allows eliminating a number of barriers that impede the growth of economic activity of economic actors, as well as decreasing high transaction expenses that hinder interaction between the participants of economic processes. The article examines the questions of creation of the information analytical platform for big data collection and processing for the purpose of researching the innovative development processes of the regional economic agents on the basis of convergent approach. The platform is intended for modular integration of instrumental means that resolve the tasks of searching, collection, processing and upload of data for intellectual analysis of the indicators of innovative activity of enterprises. The results of intellectual analysis are used for the assessment and forecast modelling of the dynamics of integral criteria of the regional innovative development, identification of innovative leaders, comparative benchmarking analysis between economic agents and leaders, synthesis of cybersocial strategies for managing the mechanisms of innovative development and formulation of recommendations on enhancing the efficiency of innovative activity of enterprises. The authors conduct the analysis of convergent and hyper-convergent systems, as well as substantiate the need for creation of the convergent platform for collection and analytical processing of big data regarding the innovations and innovative enterprises in the regions. The authors propose the principles of structuring the dataflow architecture of data integration system for solving the tasks of searching, parallel processing and upload of information onto cloud storage and distributed register. The key components of the convergent information analytical platform are being reviewed.
Keywords:
innovation system, innovation, digitalization, syber-social system, convergence, convergent platform, intellectual analysis, Big Data, regional system, transaction costs
This article written in Russian. You can find original text of the article here
.
Введение
Повсеместное внедрение современных технологий цифровой экономики позволяет устранить ряд барьеров, препятствующих росту экономической активности субъектов хозяйственной деятельности и снизить высокие трансакционные издержки, затрудняющие взаимодействие участников экономических процессов. Достижения в области технологий работы с большими данными позволяют синтезировать и исследовать новые механизмы для оценки эффективности процессов взаимодействия участников социально-экономических систем в регионах на основе интеллектуального анализа больших данных полученных из открытых источников сети Интернет. Целью является разработка комплексной системы управления инновационным развитием и конкурентоспособностью предприятий, которая является важным компонентом цифровой экономики стран и регионов. Необходимость такой системы подтверждается тем, что в регионах и странах существует неоднородность, разнообразие и отличия финансово-экономических условий для перехода к информационным технологиям и формирования инновационной среды, объединяющей субъектов цифровой экономики. Актуальность исследований обусловлена множеством причин, к которым можно отнести уровень экономического развития региона, степень финансовой обеспеченности, социальное расслоение, уровень доступного образования, наличие квалифицированных кадров, исторические аспекты развития, предпочтения и привычки, особенности места проживания и т.п. Также следует отметить факт отсутствия необходимого уровня взаимодействия между участниками из-за высоких транзакционных издержек, что не позволяет эффективно использовать системный потенциал и снижает эффективность инновационного развития всего региона. Согласно неоинституционального подхода инновационная система региона должна рассматриваться через понятия категорий институтов и трансакционных издержек [1]. Целью оптимизации систем является минимизация трансакционных издержек экономических агентов, высокий уровень которых является барьером развития инновационной деятельности.
В настоящее время сложилась ситуация, когда возможности информационно-вычислительных систем позволяют решать задачи, которые ранее решались в течение большого времени и требовали значительных ресурсов. В качестве примера можно привести маркетинговые задачи определения показателей производства и реализации товаров, которые соответствуют существующему и прогнозному спросу потребителей. Решение данных задач фактически определяет планирование объема и сроков выпуска требуемой продукции с указанием количественных и качественных показателей ассортиментного перечня товаров. Рынок покупателей крайне неоднороден. Есть различия в поведении покупателей, характерные для разных регионов. Это обусловлено существующими финансовыми и экономическими возможностями потребителей, предпочтениями, привычками, особенностями места проживания и т.п. Таким образом, для управления процессами производства и продажи товаров необходимо рассчитать прогнозные количественные и качественные оценки потенциала всех торговых точек в регионах страны с учетом геопространственного местоположения и характеристик потребительского спроса разных социальных групп населения для различных категорий ассортиментного перечня товаров, продаваемых в каждом регионе. Для решения столь масштабной задачи требуются модели и методы интеллектуального анализа больших данных о характеристиках всех торговых объектов в регионах, о продаваемых товарах согласно ассортиментным матрицам каждого магазина, которые могут включать десятки тысяч наименований, об особенностях продаж и предпочтениях жителей конкретной местности, о различных факторах влияния, таких как сезонность, уровень доходов, транспортная доступность и т.д. Весь объем данных должен быть получен в процессе автоматизированного сбора данных из открытых источников сети Интернет [2]. Конечной целью является помощь административному персоналу в принятии управленческих решений, направленных на оптимизацию работы торгового предприятия с ориентацией на лидеров торговли в регионах путем синтеза индивидуальных ассортиментных матриц и увеличение объема продаж с целью повышения конкурентоспособности.
Аналогичные проблемы возникают при управлении процессами инновационного развития и конкурентного взаимодействия любыми субъектами цифровой экономики [3]. На первый план выходят задачи сбора и обработки больших данных о всех инновационно-активных предприятиях и инвесторах. Полученная информация необходима для оценки инновационного потенциала, инвестиционной привлекательности и конкурентоспособности предприятий регионов, прогнозирования динамики развития их инновационной активности в краткосрочной и среднесрочной перспективе.
Для решения данных задач требуется комплекс методов интеллектуального анализа, который включает модели и методы стратификации, иерархической кластеризации, многофакторного дисперсионного анализа, ранжирования предприятий, оценки и выбора инновационных лидеров, бенчмаркинг-анализа, прогностического моделирования и оценки стратегий инновационного развития и динамики конкурентоспособности и т.п. Фактически здесь реализуется конвергентный подход, который определяет процесс сближения разнородных информационных технологий в результате их эволюционного развития и взаимодействия для решения задач управления инновационной системой региона [4]. Комплекс моделей и методов для оценки инновационного потенциала и конкурентоспособности предприятий в современных рыночных условиях с учетом кризисных явлений предлагается реализовать в виде конвергентной системы распределенной обработки больших данных на основе параллельной потоковой архитектуры с применением технологий блокчейн для обеспечения безопасного взаимодействия агентов инновационной системы.
Конвергентный подход, конвергентные и гиперконвергентные системы
Термин конвергенция введен в 2002 г. М. Роко и У. Бейнбриджем для определения процесса сближения нано-, био-, информационных, когнитивных и социальных технологий [5,6]. В IT-сфере конвергенция связана с развитием информационных и телекоммуникационных технологий. Научно-технологическая конвергенция [7] определяет процесс взаимопроникновения технологий и стирания границ между ними, когда результаты и инновации появляются в междисциплинарной области знаний. Иногда процесс конвергенции рассматривается в качестве синонима целостного системного подхода, в основе которого лежит принцип интеграции и свойство является эмерджентности, когда новые качества у целостной системы появляются в результате соединения ее частей. Конвергентный подход, по нашему мнению, это результат синергетического взаимодействия [8] и взаимовлияния когнитивных, социальных, информационных, телекоммуникационных, нейробиологических технологий в процессе синтеза инструментария получения новых знаний и инноваций. Приведем пример. Процесс конвергенции технологий и систем стационарной и мобильной телефонной связи привел к тому, что абонентам доступны практически идентичные услуги, а сами системы связи тесно взаимодействуют друг с другом, но это не означает, что они интегрируются.
Результатом конвергентных процессов является развитие киберфизических и киберсоциальных систем и технологий в качестве мульмодальных инфраструктурных проектов. Киберфизические системы включают природные и технические объекты со встроенными системами дистанционного мониторинга и управления, сетевыми интерфейсами [9]. Таким образом, концепция киберфизического мира определяет системно-синергетический процесс интеграции вычислительных и физических систем и процессов в рамках единой среды Интернета вещей.
Классическим примером киберсоциальных систем, влияющих на развитие общества, становятся социальные сети. Они представляют собой социальный интеллект и общечеловеческую память в виртуальном пространстве, а также являются инструментарием для целенаправленного управления общественным сознанием [10]. Киберсоциальная система рассматривает отдельных индивидов (знаний, способностей, социально-культурных особенностей) в качестве неотъемлемой части системы наряду с физическим пространством [11].
В условиях цифровой трансформации экономики региональную инновационную систему с механизмом сетевого взаимодействия ее участников также можно определить, как киберсоциальную систему мезоэкономического уровня, объединяющую экономических агентов, формальные и неформальные институты, информационную среду, аналитическую платформу для обработки и хранения данных с элементами искусственного интеллекта для поддержки принятия решений, систему распределенного реестра для обеспечения безопасности и т.п. Следует отметить, что элементы любой киберсоциальной системы зависят от обеспечения безопасного и надежного доступа к основным информационным ресурсам.
Конвергенция технологий, как фактор современных эволюционных процессов, уже оказывает положительное влияние на инновационные процессы в экономических системах. Технологии сетевого взаимодействия, социальные сети, искусственный интеллект, технологии обработки больших данных, Интернет вещей, платформы блокчейн и смарт-контракты изменяют продукты конечного потребления, средства их производства, логистические процессы.
Конвергентные системы обработки и хранения данных открывают новый этап развития информационно-телекоммуникационной инфраструктуры [12,13]. Часто, конвергентной инфраструктурой называют сетевые вычислительные комплексы, содержащие все необходимое для решения задач организации. Фактически конвергентная система строится на базе такой инфраструктуры, которая включает сенсорные сети и Интернет вещей, облачные вычислительные кластеры, мультипроцессорные системы, системы мобильных вычислений.
Следующим этапом эволюционного развития конвергентных систем являются становятся гиперконвергентные инфраструктуры корпоративного уровня [14].
Отличие конвергентных и гиперконвергентных систем состоит в том, что конвергентные структуры включают специализированные компоненты (вычислительные, узлы хранения данных и т.п.), которые взаимодействуют друг с другом. Гиперконвергентные системы представляют модульные решения, разработанные для простоты масштабирования посредством включения в систему новых модулей. Мощность конвергентных систем решается путем вертикальной масштабируемости (scale-in), когда увеличение возможностей программно-аппаратных средств выполняется путем добавления специализированных ресурсов, например, для повышения мощности системы хранения данных добавляются новые диски и модули вводавывода по мере необходимости. Гиперконвергентные системы решают аналогичную задачу путем горизонтальной масштабируемости (scale out), которая означает интеграцию автономных модулей так, чтобы они становились единым комплексом. При этом модули могут быть удалены географически. Новые модули могут включаться в систему практически без ограничений по мере требования. Автономные модули объединяются в кластеры, связанные через внешнюю сеть. В процессе администрирования кластер рассматривается как единая логическая единица, где информационные объекты представлены в глобальном пространстве имен или в распределенной файловой системе.
Аналитическая исследовательская компания Forrester Research [15] отмечает, что гиперконвергентный подход к созданию IT-инфраструктуры позволяет объединить в модульной конфигурации серверы, системы хранения, сетевые функции и программное обеспечение, отвечающее за создание пула информационных и вычислительных ресурсов [16]. Гиперконвергентная система состоит из модулей, объединенных в горизонтально-масштабируемый кластер [17]. Каждый модуль включает вычислительное ядро, ресурс хранения, телекоммуникационную компоненту и гипервизор для решения задач распределения ресурсов и управления масштабированием. Гиперконвергентная система реализует концепцию программно-определяемых сред (software-defined environment), в которых ресурсы виртуализируются на уровнях вычислительного кластера, системы хранения данных, телекоммуникационной сети, а управление автоматически реализуются на программном уровне. Такие решения эффективны для задач, где необходимо обеспечить безопасность и отказоустойчивость за счет унифицированной инфраструктуры, состоящей из одинаковых модулей. Поэтому преимуществами гиперконвергентных систем является более низкая стоимость, простота администрирования, масштабируемость, точное соответствие ресурсов потребностям предприятия.
В настоящее время гиперконвергентные платформы предоставляют программно-аппаратные решения для обработки и анализа больших данных (СУБД, серверы приложений, среды разработки, средства обеспечения безопасности и т.п.). К ним можно отнести аппаратно-программные комплексы от Teradata [18], Exa-комплексы от Oracle [19,20], комплексы экосистемы Hadoop [21] Платформа IBM InfoSphere BigInsights платформа IBM Big Data с комплексом средств обработки и анализа больших данных [22] и др. Другим примером гиперконвергентных систем являются программно-аппаратные блокчейн платформы [23].
Конвергентная информационно-аналитическая платформа
Конвергентная аналитическая платформа представляет собой совокупность программно-аппаратных средств, взаимодействующих между собой, которые предназначены для автоматизации процессов сбора и обработки больших данных с использованием вычислительного кластера, облачных технологий и мобильных систем связи. Платформа включает: а) комплекс вычислительных средств центра обработки данных, б) комплекс средств сбора, обработки и загрузки данных в хранилище, облачное хранилище данных, в) прикладные программные комплексы для решения задач интеллектуального анализа и прогноза, г) экспертную подсистему для настройки прогнозных и аналитических моделей, д) систему удаленного доступа, е) систему администрирования информационной безопасности, ж) средства мониторинга и управления функционированием системы.
Информационно-аналитическая платформа представляет собой конвергентную систему для автоматизации процессов мониторинга и поддержки принятия решений за счет интеграции инструментальных средств поиска, сбора, обработки, консолидации и хранения данных, расчета интегральных показателей, интеллектуального анализа и прогностического моделирования динамики их изменений, формирования отчетности и предоставления ее пользователям в наглядном виде, администрирования информационной безопасности. Она обеспечивает координацию шагов технологического процесса обработки информации в системе мониторинга и поддержки принятия решений, осуществляет централизованный мониторинг и аудит функционирования ее компонент.
Информационно-аналитическая поддержка процессов принятия решений с помощью разработанной платформы осуществляется путем консолидации и многоцелевого использования оперативных и ретроспективных данных об инновационной деятельности экономических агентов в облачном хранилище и представления результатов мониторинга в витринах данных на компьютерах и мобильных средствах связи пользователей. Работа инструментальных средств аналитической платформы состоит в автоматизации процесса сбора и обработки больших данных об инновациях и инновационных предприятиях в регионах из открытых источников в сети Интернет для комплексного интеллектуального анализа и прогностического моделирования инновационных процессов в регионах. К основным реализуемым процедурам относятся:
· Поиск информации в открытых источниках, сбор данных и извлечение данных о показателях и индикаторах инновационной деятельности предприятий, о факторах влияния на процессы инновационного развития.
· Подготовка и загрузка данных в центральное облачное хранилище для интеллектуального анализа и прогноза с реализацией централизованной технологии обработки и хранения больших данных для принятия решений.
· Мониторинг показателей инновационной деятельности хозяйствующих субъектов и всего региона в целом.
· Выбор инновационных лидеров в регионах и определение набора значений эталонных показателей инновационной деятельности и конкурентоспособности в каждом регионе для учета особенностей регионального развития.
· Синтез прогнозных моделей и прогнозирование динамики показателей инновационной активности и конкурентоспособности экономических агентов в краткосрочной и среднесрочной перспективе для трех сценариев развития (оптимистического, пессимистического и оптимального).
· Сравнительный анализ (бенчмаркинг) показателей инновационной деятельности и конкурентоспособности экономических агентов в регионе с эталонными показателями инновационных лидеров с целью синтеза стратегий их инновационного развития и принятия решений по повышению инновационной активности и конкурентоспособности [24].
· Генерация информационно-аналитических отчетов для заинтересованных лиц с результатами анализа и прогноза с целью синтеза рекомендаций по повышению инновационной активности и конкурентоспособности экономических агентов в регионах и предоставление персонализированного доступа к информационно-справочным и аналитическим материалам.
Продукцией платформы являются статистические и аналитические отчеты в цифровой, текстовой, графической или смешанной форме представления, доступ к которым предоставляется пользователям согласно групповым политикам взаимодействия в и принятым протоколами безопасности. За счет сбора, накопления и анализа оперативной и ретроспективной информации о состоянии экономических агентов и инновационной деятельности в регионах достигается расширение информационной базы управления. Повышение эффективности управления обеспечивается путем централизованного предоставления пользователям основных видов аналитической, статистической и прогнозной отчетности о инновационной активности объектов анализа на основе достоверных, полных и непротиворечивых данных, накопленных в централизованном облачном хранилище.
Преимущества использования информационно-аналитической платформы:
1. Централизации обработки и хранения данных об инновационной деятельности;
2. Контроль целостности и неизменности данных, полученных из открытых источников;
3. Обеспечения непротиворечивости и полноты информации для принятия решений по изменению инновационной активности в регионах;
4. Повышение эффективности принятия решений по улучшению инновационного климата в регионах за счет оперативности предоставления нужной информации.
Конвергентная платформа формирует среду функционирования прикладных бизнес приложений, которые выполняют: а) централизованную обработку данных, б) консолидированное хранение данных, в) синтез информационных продуктов, г) предоставление результатов анализа данных. Функционал среды реализуется сервисами: а) взаимодействия с пользователями, централизованного доступа пользователей к данным, формирования информационных продуктов и регламента их использования, разграничения доступа к отчетам, контроля качества отчетов, получения, накопления, консолидированного хранения и интеграции данных, управления функционированием подсистем и взаимодействием между ними. Основными требованиями к конвергентной платформе являются [25]:
1. Архитектура платформы должна быть рассчитана на поиск и подключение новых источников данных с минимальным числом изменений компонент, поэтому компоненты платформы проектируются, исходя из свойств модели данных.
2. Платформа должна обеспечивать производительность путем эффективного распределения ресурсов без доработки программного обеспечения.
3. Платформа реализует возможность повторного использования проектных решений для снижения затрат за счет синтеза набора шаблонных модулей, которые можно настраивать или дорабатывать при необходимости расширения.
Информационно-аналитическая платформа реализует несколько уровней обработки информации: а) уровень источников данных, б) уровень интеграции данных, в) уровень хранения данных, г) уровень аналитической обработки данных, д) уровень доступа.
На уровне источников данных решаются задачи сбора и первичной обработки данных из различных источников в сети Интернет и представление их в формате XML. На уровне интеграции данных определяются методы консолидации и загрузки данных, процессы контроля данных, технологии извлечения и преобразования неструктурированных и слабо структурированных данных, загрузки структурированных данных в облачное хранилище. Здесь пакетная обработка больших данных реализуется процедурами ETL (Extraction, Transformation, Loading). Уровень хранения данных реализуется посредством СУБД облачного хранилища. На уровне аналитической обработки работают инструментальные средства интеллектуального анализа и прогнозирования. Уровень доступа определяет технологии персонализированного доступа к данным и результатам с использованием web сервисов и мобильных приложений. Архитектура конвергентной платформы включает следующие модульные программные компоненты:
1. Модуль хранения данных на базе облачного хранилища обеспечивает хранение ретроспективных данных, поступающих из системы интеграции, значений интегральных показателей, отчетов.
2. Модуль интеграции данных обеспечивает консолидацию данных, очистку данных, преобразование данных для загрузки в хранилище и передаче в аналитическую систему.
3. Модуль формирования отчетов на основе информации из хранилища согласно регламенту или по запросам пользователей.
4. Модуль ведения метаданных обеспечивает синтез и описание метаданных для первичных данных, сущностей облачного хранилища и витрин данных. Для первичных данных обеспечивает описание инфологической модели данных в терминах предметной области. Для сущностей хранилища обеспечивает описание и управление на трех уровнях: физическом, логическом и инфологическом.
5. Модуль взаимодействия с пользователем обеспечивает сервисы контролируемого доступа к информационным продуктам в соответствии с правами и разрешениями.
6. Модуль персонализированного доступа к данным и результатам мониторинга обеспечивает подготовку, преобразование и публикацию данных через веб-сервис и мобильное приложение.
7. Модуль администрирования обеспечивает автоматизацию деятельности системных администраторов по управлению функционированием и взаимодействием модулей и аппаратных компонент платформы.
Конвергентная платформа реализует такие модели облачных вычислений, как Platform-as-a-Service (PaaS) и Infrastructure-as-a-Service (IaaS). Модель PaaS предоставляет потребителю возможность использования облачной инфраструктуры для размещения и запуска приложений обработки данных. Модель IaaS предоставляет возможность использования облачной инфраструктуры для управления ресурсами обработки и хранения данных. Для поддержки технологии конвергентной обработки больших данных реализованы программно-аппаратный комплекс виртуализации и комплекс терминального доступа к результатам. Программно-аппаратный комплекс виртуализации обеспечивает:
- функционирование модульных серверов в виртуальной среде на архитектурной платформе х86,
- ввод в работу новых виртуальных серверов в процессе масштабирования,
- управление вычислительными ресурсами для работы программных модулей.
Программно-технический комплекс терминального доступа обеспечивает:
- сервис облачного доступа к виртуальной среде пользователя с использованием технологии виртуальных рабочих станций,
- сервис облачного доступа к виртуальной среде администратора с использованием технологии виртуальных рабочих станций;
- интерфейс виртуальной рабочей станции на мобильных средствах связи.
Платформа разрабатывается на языке Java в среде Java EE в кроссплатформенном исполнении для ОС z/OS, AIX, Linux и Windows и предназначена для ЭВМ класса mainframe (RISC, Intel x86). Для работы компонент платформы в центре обработки данных используется UNIX-подобная ОС AIX (Advanced Interactive eXecutive) компании IBM и СУБД IBM DB2 for AIX. Конвергентная платформа реализуется технологию параллельной обработки больших данных в ходе выполнения ETL процедур и процедур аналитической обработки. Для поддержки технологии используется гипервизор с возможностью поддержки: а) до 320 логических процессоров на хост-сервер, б) до 4 ТБ оперативной памяти на хост-сервер, в) до 512 виртуальных машин на хост-сервер, г) автоматического распределения виртуальных машин между хост-серверами в зависимости от загрузки, д) «горячей» миграции виртуальных машин между хост-серверами, е) загрузки гипервизора с внешнего дискового массива по сети, ж) виртуальных распределенных сетевых коммутаторов.
Программно-инструментальные модули платформы размещаются на выделенных ресурсах программно-технического комплекса pSeries, работающего под управлением ОС AIX. Для организации облачного хранилища применяются СУБД DB2 10.1 и DB2 Spatial Extender, а модуль интеграции данных работает на базе IBM Information Server 9.1.2. Для формирования отчетов используется система Cognos BI 10.2 и IBM HTTP Server 8.0.0.0. Взаимодействие с пользователями и администрирование платформы осуществляется через сервер приложений Websphere Application Server 8.5.5. Для управления метаданными также используется следующие инструментальные средства:
1. IBM Infosphere Data Architect (для проектирования структур данных, синтеза тезауруса, моделей данных и физических объектов);
2. IBM Infosphere Information Server, в состав которого входят:
· IBM Infosphere Business Glossary (для создания, управления и просмотра словаря терминов предметной области инновационной деятельности);
· IBM Infosphere Metadata Repository (для поддержки хранилища метаданных);
· IBM InfoSphere Metadata Workbench (для просмотра и управления метаданными);
· IBM Infosphere Asset Manager (для импорта метаданных);
· IBM Infosphere Datastage Designer (для синтеза ETL процедур);
· IBM Infosphere Fasttrack (для создания спецификаций данных);
3. Geoserver (для работы и публикации геопространственных данных посредством WFS-сервера).
Архитектура системы интеграции для потоковой обработки данных
Как уже было сказано, главным свойством конвергентных и гиперконвергентных систем является масштабируемость архитектуры, что позволяет увеличивать производительность и количество обрабатываемой информации без кардинальной модернизации всей системы. Это свойство делает такие системы незаменимыми для работы с большими данными. В качестве примера рассмотрим архитектуру конвергентной системы интеграции данных или ETL системы. ETL система реализует ряд процессов обработки данных и управления ходом обработки, к которым относятся:
1. Извлечение данных, поступающих от источников.
2. Конвертирование данных из различных источников в единый формат представления.
3. Обеспечение качества и целостности данных в хранилище и восстановление их в случае нештатных ситуаций.
4. Преобразование данных (очистка, нормирование и консолидация) в ходе загрузки в хранилище.
5. Загрузка данных и актуализация ранее загруженных данных в хранилище.
6. Мониторинг, контроль и протоколирование процессов загрузки данных.
7. Выявление и обработка ошибок, возникающих в процессе интеграции данных.
Извлечение данных – это процесс захвата данных и переноса в область подготовки данных. Конвертирование данных представляет процесс унификации данных, приходящих в различных форматах. При этом выполняется преобразование данных в соответствии с локальными справочниками, соответствующими источнику информации, стандартизация идентификаторов элементов данных и структуры представления данных. Обеспечение качества является процессом, в ходе которого данные из области подготовки проверяются на в соответствии с критериями корректности, полноты, непротиворечивости, согласованности и унификации. Преобразование данных представляет процесс их очистки, дополнения или модификации в соответствие с логикой обработки. В ходе загрузки данных выполняется перенос данных из области преобразования в хранилище.
Проблема масштабируемости решается за счет синтеза конвергентной архитектуры, обеспечивающей высокую степень параллельной обработки больших данных с возможностью управления степенью параллельности. Распараллеливание процессов позволяет эффективно использовать аппаратные ресурсы и задействовать дополнительные ресурсы при увеличении числа источников данных. Это предполагает подключение и использование шаблонных модулей обработки данных [26,27]. Тогда конвергентную систему интеграции данных можно представить в виде набора модульных потоков, взаимодействующих между собой [28]. Каждый модульный поток реализует полный процесс обработки данных от извлечения из источников до загрузки в хранилище (Рис. 1).
 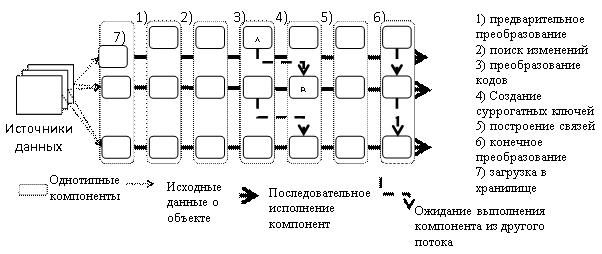
Рис. 1. – Потоковая архитектура конвергентной системы интеграции данных
Архитектура системы интеграции проектируется согласно свойствам корпоративной модели данных хранилища. Объект региональной инновационной системы представляется логическим понятием или совокупностью. Также логическое понятие может быть событием, случившимся в источнике данных с одним или несколькими объектами. Каждый поток в архитектуре выполняет экстракцию, преобразование и загрузку данных об одном логическом понятии. Каждый объект и событие включают набор атрибутов, включающих:
· Бизнес–ключ (B) – атрибут для идентификации экземпляра объекта (логического понятия) инновационной системы или события (например, регистрационный номер патента) в источнике. Состав бизнес-ключей определяется на основе описания процесса инновационной активности.
· Уникальный идентификатор объекта инновационной системы в источнике (K) - атрибут строкового типа для идентификации экземпляра одинакового логического понятия в разных источниках и выделения ETL операций для одинакового объекта в разных потоках.
· Суррогатный ключ (S), который служит первичным ключом и генерируется на основе набора значений бизнес-ключей так, чтобы набору значений соответствовало единственное значение суррогатного ключа.
· Уникальный ключ (U) - атрибут, идентифицирующий экземпляры объектов, участвующих в событии или связанные с объектом (например, ИНН или ОГРН инновационного предприятия), на основе которых определяются внешние ключи.
· Уникальный внешний идентификатор в источнике (L) - атрибут строкового типа для идентификации экземпляра понятия в составе другого понятия в различных источниках и выделения ETL операций для одинакового понятия в разных потоках.
· Внешний ключ (O) - атрибут, образующий связи между логическими понятиями в инфологической модели хранилища.
· Справочные атрибуты (F) – атрибуты, содержащие информацию в виде значений справочников источников данных, а также атрибуты справочников хранилища, получаемые в результате преобразования атрибутов источников.
· Мнемонический код справочника (R) - атрибут строкового типа, который позволяет идентифицировать значения локальных справочников в источниках данных и вводится для определения общих операций в потоках.
· Информационные атрибуты (I) – атрибуты, содержащие информацию об объекте инновационной системы.
· Технические атрибуты (С) – атрибуты, содержащие техническую информацию хранилища.
Тогда метаданные M для объекта A и события E можно представить, как совокупность множеств: M (A, E) = {B, K, S, U, L, O, F, R, I, C}. Каждый компонент потока выполняет соответствующее преобразование атрибутов из входных метаданных в атрибуты выходных метаданных. Таким образом поток состоит из компонент, которые реализуют функции:
1) Сбор данных, относящих к логическим понятиям;
2) Предварительное преобразование;
3) Поиск изменений (новых данных об объектах);
4) Преобразование значений классификаторов из источников в значения хранилища;
5) Создание суррогатных ключей на основе бизнес-ключей и построение справочника соответствия суррогатных ключей бизнес-ключам в различных источниках;
6) Синтез связей (назначение корректных внешних ключей) между бизнес-ключей;
7) Конечное преобразование (разбор данных по структуре физических таблиц хранилища);
8) Загрузка данных в базу данных хранилища.
В составе одного потока ETL процедуры выполняются последовательно: каждая процедура обрабатывает результат предыдущей. Потоки зависят от исходных данных на этапе «Предварительное преобразование» и могут взаимодействовать на этапах «Синтез связей» и «Загрузка данных». Функция «Предварительное преобразование» может потребовать неизвестное количество операций над данными, так как здесь реализуются алгоритмы, зависящие от источников. Состав операций, выполняемых в остальных компонентах известен и определяется внутренними функциями системы. Для компонента можно создать шаблон, включающий типовой набор операций. Таким образом конвергентная система состоит из потоков и однотипных компонент, отличающихся входными и выходными метаданными. Архитектура эффективна при такой информационной модели, в которой рост объема данных ведет к добавлению новых объектов, но не меняет существующие объекты. Так как существующие объекты не изменяются, то без изменений остаются потоки, их обрабатывающие. Для загрузки новых объектов просто добавляются новые потоки.
В конвергентной архитектуре потоки взаимодействуют между собой, например, ждут завершения работы предыдущего компонента другого потока. При этом система не простаивает, так как параллельно работают другие потоки при выполнении ETL заданий. Потоки выполняются на распределенных физических ресурсах в GRID-архитектуре, решая задачу масштабирования. Число параллельно исполняемых потоков может регулироваться для уменьшения или увеличения утилизации ресурсов.
Заключение
Основной целью применения инструментальных средств информационно-аналитической платформы является реализация методологии интеллектуального анализа и прогностической оценки инновационной активности региональных систем. Однако для анализа и оценки необходимо определить перечень показателей инновационной деятельности и разработать интегральные критерии инновационного развития как отдельных экономических агентов, так и всего региона в целом. Данные для формирования перечня показателей инновационной активности составляют базис инновационного развития регионов. В качестве комплексного критерия инновационного развития региона можно использовать интегральную оценку инновационного потенциала и инвестиционной привлекательности предприятий и организаций в регионах. В качестве результативных показателей могут выступать: средний объем инвестиций для внедрения инноваций за исследуемый период времени, максимальный объем инвестиций для внедрения инноваций за исследуемый период времени, медиана на шкале измеренных значений инвестиций, процентили (характеристики данных, которые являются показателем того, какой процент значений инвестиций предприятия находится ниже определенного уровня) и т.п.
Для расчета показателей необходимо выполнить поиск данных в открытых источниках. Сложность решения задачи поиска и извлечения данных обусловлена тем, что показателей инновационной активности может быть достаточно много, причем для исследования инновационной деятельности надо отбирать не только прямые показатели, как например, число зарегистрированных объектов интеллектуальной собственности, объем финансирования инновационных разработок, но и косвенные факторы, оказывающие влияние на уровень инновационного развития предприятия и региона, как например, наличие и состояние транспортной инфраструктуры, уровень дохода работников предприятия и жителей региона, уровень развития информационно-телекоммуникационной инфраструктуры и средняя стоимость услуг по доступу в Интернет у сервис-провайдеров.
Поэтому на первом этапе составляется максимально возможный перечень показателей, которые прямо и косвенно характеризуются инновационное состояние предприятий и организаций в регионах. Затем выполняется поиск данных, необходимых для расчета показателей за заданные интервалы времени, чтобы построить графики динамики их изменений и оценить как изменения показателей влияют на интегральные критерии инновационного развития. Далее необходимо провести исследования показателей на предмет оценки чувствительности к ним интегральных критериев и методом многофакторного дисперсионного анализа определить подмножество наиболее чувствительных показателей, которые с позиции системно-синергетического подхода принято называть параметрами порядка. Подмножество параметров порядка в дальнейшем будет использовано для синтеза многомерного пространства для группирования предприятий в кластеры инновационного развития и определения лидеров инновационного развития по оптимальным значениям показателей. В процессе кластеризации необходимо учесть данные о местоположении предприятий, экономические, культурные, социальные и прочие особенности региона, где они находятся. Для решения данной задачи разработана методика стратификации, согласно которой выполняется выделение страт населенных пунктов, в которых находятся исследуемые предприятия. Критерии стратификации должны учитывать уровень социально-экономического развития населенных пунктов, численность населения, наличие квалифицированных кадров для решения задач инновационного развития, развитие транспортной и телекоммуникационной инфраструктуры и т.п. Таким образом решение задачи кластеризации должно выполняться не только для регионов, но и для отдельных страт в них. Это говорит о необходимости использовать метод иерархической многослойной кластеризации, так как кластеризацию одновременно надо проводить в слоях согласно отраслям экономики.
Исходными данными для анализа больших данных об инновационных экономических агентах в регионах являются:
1. Геопространственные данные о местоположении экономических агентов;
2. Данные о наличии ресурсов у предприятий для решения инновационных задач;
3. Данные о финансовом состоянии экономических агентов;
4. Данные об разработанных, проданных и внедренных инновациях за заданный интервал времени с разбивкой по годам и месяцам;
5. Данные об объемах собственных финансовых ресурсов, затраченных на разработку и внедрение инноваций за заданный интервал времени с разбивкой по годам и месяцам;
6. Данные об объемах внешних инвестиций, затраченных на разработку и внедрение инноваций за заданный интервал времени с разбивкой по годам и месяцам;
7. Данные о зарегистрированных объектах интеллектуальной собственности;
8. Данные о транспортной инфраструктуре региона;
9. Данные о телекоммуникационной инфраструктуре в регионе и т.д.
Основной сложностью является обработка огромного объема (порядка нескольких десятков терабайт) информации, представленной в структурированном и в неструктурированном виде, в источниках сети Интернет. Для решения задач сбора и обработки больших данных применяется потоковая механизм, реализованный в конвергентной GRID системе интеграции данных. Извлечение данных из открытых источников реализуется множеством поисковых агентов, которые собирают данные об объектах инновационной деятельности в регионах, включая геопространственную информацию, наименование, финансовые показатели, данные об объектах интеллектуальной собственности, данные о кадровых, материальных и информационных ресурсах прелприятий и т.п. Источниками данных являются сайты предприятий, сайты государственных служб, специализированные базы данных, сайты предприятий-партнеров. Агенты реализованы в виде специализированных поисковых краулеров на языке Python Scrappy. Данные о одинаковых объектах из разных источников должны быть объединены между собой. Для этого решается задача сопоставления адресов, наименований, спутниковых координат с целью исключения дублирующей информации. Эффективным способом является последовательное прямое (преобразование адреса в координаты) и обратное (преобразование координат в адрес) геокодирование с помощью сервисов Yandex Геокодер или Nominatium. Для объединения информации о конкретном инновационном объекте из разных источников применяются встроенные средства базы данных PosgreSQL. Для очистки адресов используются правила, написанные на языке plpgsql в PosgreSQL. Каждое из правил направлено на удаление или замену алфавитно-цифровых символов, букв и аббревиатур в процессе перевода адреса в структурированный вид с последующим геотеггированием. В процессе геотеггирования выполняется добавление к описанию объекта его спутниковых координат, недостающих данных в почтовом адресе. Процедура включает обратную проверку валидности геопространственной информации. Полученный блок данных с информацией об инновационном объекте загружается в центральное хранилище. Для обеспечения надежного хранения информации об инновационном объекте и реализации возможности безопасного обмена информационных блок хэшируется и заносится в созданный распределенный реестр на блокчейн платформе Etherium, который разработан для реализации смарт контрактов по передаче прав интеллектуальной собственности на инновации между участниками инновационной деятельности [29].
Благодарности. Результаты работы получены при финансовой поддержке РФФИ в рамках грантов № 16-07-00031, 18-010-00204, №18-07-00975
References
1. Gamidullaeva, L.A. Instituty v razvitii innovatsionnykh sistem. Journal of Economic Regulation. 2016. T. 7. № 1. S. 93-103.
2. Novye metody raboty s bol'shimi dannymi: pobednye strategii upravleniya v biznes-analitike: Nauchno-prakticheskii sbornik / A. V. Shmid i dr., M.: PAL''MIR, 2016. – 528s.
3. Bershadskii A.M., Berezin A.A., Finogeev A.G. Informatsionnoe obespechenie instrumental'nykh sredstv prinyatiya reshenii po upravleniyu konkurentosposobnost'yu // Russian journal of management M.: Izdatel'skii Tsentr RIOR.-2017.-t. 5.-№ 3. – s. 490-493.
4. Bainbridge, M.S., Roco, M.C. Managing Nano-Bio-Info-CognoInnovations : Converging Technologies in Society. NY: Springer, 2005. 390 p.
5. Finogeev A.G. Proactive Urban Computing: an Active Agent-Based Concept and Methods / D. Parygin, M. Shcherbakov, N. Sadovnikova, A. Kravets, A. Finogeev // SMART-2017 : Proceedings of the 6th International Conference on System Modeling & Advancement in Research Trends, Moradabad, India, 29–30 December 2017. – IEEE, 2017. – P. 219–226.
6. Roco M., Bainbridge W. Converging Technologies for Improving Human Performance: Nanotechnology, Biotechnology, Information Technology and Cognitive Science. Arlington, 2004. URL:http://www.wtec.org/ConvergingTechnologies/Report/NBIC_report.pdf
7. Lee Chul, Park Gunno ,KangJina The impact of convergence between science and technology on innovation, The Journal of Technology Transfer, 2016, p. 1 – 23
8. Finogeev A.G. Modelirovanie issledovaniya sistemno-sinergeticheskikh protsessov v informatsionnykh sredakh: Monografiya, Penza: Izd-vo PGU, 2004, 223 s.
9. Finogeev, A.G., Parygin, D.S. & Finogeev, A.A. (2017) The convergence computing model for big sensor data mining and knowledge discovery / Human-centric Computing and Information Sciences.-Vol. 7. – p. 11. doi:10.1186/s13673-017-0092-7. URL: http://link.springer.com/content/pdf/10.1186%2Fs13673-017-0092-7.pdf.
10. Finogeev A.G. Monitoring of social reactions to support decision making on issues of urban territory management /S. Ustugova, D. Parygin, N. Sadovnikova, A. Finogeev, A. Kizim// Procedia Computer Science: Proceedings of the 5th International Young Scientist Conference on Computational Science, YSC 2016, Krakow, Poland, 26-28 October 2016. – Elsevier, 2016. – Vol. 101. – P. 243-252.
11. Liu Z. et al. Cyber-physical-social systems for command and control //IEEE Intelligent Systems. – 2011. – T. 26. – №. 4. – S. 92-96.
12. Broderick, Katherine and Scaramella, Jed. (2010) "Considering All of IT: Converged Infrastructure Survey Findings," IDC, June 2010,
13. George J. Weiss (2015). "Plan Now for the Future of Converged Infrastructure". Gartner. Retrieved 8 February 2016
14. Patrick Hubbard. "Hyper-converged infrastructure forcing new thinking for networks". Techtarget. Retrieved 8 February 2016, Darryl K. Taft. "IBM Sees Flash, Hyper-convergence Among Top 2016 Storage Trends". Eweek. Retrieved 8 February 2016
15. Cait kompanii Forrester Research. [Elektronnyi resurs] www.forrester.com [Data obrashcheniya: 10.06.18]
16. Whiteley, Robert. Forrester Research."Your Next IT Budget: 6 Ways to Support Business Growth," CIO Magazine Archived 2011-07-21 at the Wayback Machine., July 21, 2010
17. John Rollason (5 June 2017). "Introducing NetApp Enterprise-Scale HCI: The Next Generation of Hyper Converged Infrastructure". NetApp. Archived from the original (url) on 2018-01-23. Retrieved 13 January 2018
18. Cait korporatsii Teradata. [Elektronnyi resurs] https://www.teradata.ru/ [Data obrashcheniya: 10.06.18]
19. Exadata, Exalogic, Exalytics) [Osborne, Kerry; Johnsn, Randy and Põder Tanel. Expert Oracle Exadata. — N. Y.: Apress, 2011. — 500 p.
20. Plunkett, Tom; Palazzolo, TJ; Joshi, Tejas. Oracle Exalogic Elastic Cloud Handbook. — N. Y.: McGraw-Hill, 2011. — 432 p.
21. White, Tom. Hadoop: The Definitive Guide. — 2-nd edition. — Sebastopol: O’Reilly Media, 2011. — 600 p.
22. Big Data Analytics. [Elektronnyi resurs] http://www.ibm.com/big-data/us/en/conversations/ [Data obrashcheniya: 10.06.18]
23. Blokchein platformy. [Elektronnyi resurs] http://smart-contracts.ru/platforms.html [Data obrashcheniya: 10.06.18]
24. Mkrttchian, V., Bershadsky, A., Finogeev, A., Berezin, A., Potapova, I. (2017). Digital Model of Bench-Marking for Development of Competitive Advantage (279-300pp.). In Pedro Isaias and Luisa Carvalho (Eds). User Innovation and the Entrepreneurship Phenomenon in the Digital Economy. Hershey, PA, USA: IGI Global.-Chapter 14. – P. 288-304. DOI: 10.4018/978-1-5225-2826-5. URL: https://www.igi-global.com/chapter/digital-model-of-bench-marking-for-development-of-competitive-advantage/189823
25. Kimball R. The Data Warehouse ETL Toolkit: Practical Techniques for Extracting, Cleaning, Conforming, and Delivering Data / R. Kimball, J. Caserta. – Wiley Publishing Inc., 2004.
26. Goma Kh. UML. Proektirovanie sistem real'nogo vremeni, parallel'nykh i raspredelennykh prilozhenii: Per. s angl. – M.: DMK Press. – 704s.
27. Kreg Larman. Primenenie UML 2.0 i shablonov proektirovaniya = Applying UML and Patterns : An Introduction to Object-Oriented Analysis and Design and Iterative Development. — M.: «Vil'yams», 2006. — S. 736.
28. Lychagin K.A., Pozin B.A. // Ustoichivaya k izmeneniyam arkhitektura sistemy integratsii dannykh RBP-SUZ-2011: Materialy konferentsii / MESI – M, 2011, s.190-194
29. Finogeev A.G., Vasin S.M., Gamidullaeva L.A., Finogeev A.A. Tekhnologiya smart kontraktov na osnove blokchein dlya minimizatsii transaktsionnykh izderzhek v regional'nykh innovatsionnykh sistemakh // Voprosy bezopasnosti. — 2018.-№ 3.-S.34-55. DOI: 10.25136/2409-7543.2018.3.26619. URL: http://e-notabene.ru/nb/article_26619.html
|

 Eng
Eng










