|
Historical informatics
Reference:
Shpirko, S. (2022). Once again to the problem of estimating the number of Genoese merchants in Byzantium at the end of the 13th century using the methods of mathematical statistics. Historical informatics, 1, 63–73. . https://doi.org/10.7256/2585-7797.2022.1.37362
Once again to the problem of estimating the number of Genoese merchants in Byzantium at the end of the 13th century using the methods of mathematical statistics
Shpirko Sergey
Associate Professor, Moscow State Historical Archives Institute, Russian State University for the Humanities
119313, Russia, g. Moscow, ul. Leninskii Prospekt, 88 korpus 3, kv. 122

|
shpirkos@mail.ru
|
|
 |
Other publications by this author
|
|
|
DOI: 10.7256/2585-7797.2022.1.37362
Received:
20-01-2022
Published:
11-05-2022
Abstract:
One of the actual problems of Byzantine studies is the estimation of the size of the Genoese trading community of Constantinople, which played a critical role in the fate of late Byzantium. To solve this problem the historian A.L. Ponomarev proposed to use mathematical methods based on data from indirect sources - notarial deeds preserved in the State Archives of Genoa. These deeds were drawn up to fix commercial transactions, agreements on the creation of commercial partnerships, the hiring of ships, wills, the purchase and sale of houses, goods and people. In addition to the obligatory mention in the deed form of the names of the contracting parties and witnesses to the transaction, it may also, depending on its type, contain the names of guardians, recipients of the will and other third parties. Thus, these data on the clientele of Genoese notaries represent a rather impressive and valuable array of information, which may indirectly indicate the size of the entire trading Genoese community of Byzantium. To solve this problem, the author of this paper draws on the ideas and methods of the theory of random placements, which is an intensively developing area of mathematical statistics. It is based on constructing a linear estimate of the value and assumes a random sample. The result obtained is compared with the estimate from the previous paper by the author, which is based on another method of mathematical statistics and is quite close to the value of A.L. Ponomarev - 688 people.
Keywords:
Constantinople, Genoese, notarial deeds, frequency of occurrence, ranged series, statistical estimation, sample, size of a finite population, linear estimate, random placement
This article is automatically translated.
You can find original text of the article here.
I. Introduction Is it possible to apply the methods and ideas of mathematical sciences to the task of replenishing the data of historical sources? In particular, this question is posed by A.L. Ponomarev in his research related to the establishment of the approximate number of Genoese merchants in Constantinople at the end of the XIII century. It is well known in historiography that, starting with the conclusion of the Nymphean Treaty in 1261, the Genoese developed a rapid commercial activity in the Byzantine possessions, as evidenced by numerous agreements on trade partnerships, hiring ships, wills, purchase and sale of houses, goods and people. However, historical sources have not preserved direct evidence about the size of their trading community. A.L. Ponomarev suggests using data from indirect sources for this purpose, namely numerous notarial acts stored in the State Archive of Genoa. These, in particular, include 149 acts of the notarium Gabriele de Predono, compiled in Pera (the center of the Genoese community of Constantinople and the second most important colony of Genoese in the Byzantine possessions after Kaffa) for the period from June to October 1281 and published by the Romanian scientist G. Bratianu in 1927 [1]. All acts are drawn up in accordance with a clear protocol, contain, among other things, the names of counterparties, witnesses, as well as third parties involved in the commercial transaction. At the same time, the same person could be specified in several acts. For example, in one contract it acts as a counterparty, in another – as a witness, in the third – as a buyer of a slave. Of course, the acts of Predono do not contain the names of all the members of the Genoese trading community of Pera. Merchants could make deals with other notaries. For example, only in Kaffa (true, in the tenth years of the XV century) at least 14 notaries worked [2, p. 8]. Small transactions could not be registered at all. However, if we proceed from the hypothesis of the randomness of the merchant's choice of one or another notary for fixing the transaction, then the data can serve as an “instant snapshot” that allows us to solve the desired problem of estimating the entire population. So, the task of our modeling is to estimate the volume of the general population based on the available sample. Moreover, this modeling is based on the idea of the process of drawing up a notary act and mentioning individual personalities in it as the selection of appropriate elements from the general (general) totality. Since the same personalities can be mentioned in several acts, such a process is a choice with a return. In a previous paper, we investigated the distribution of the number of different elements in the sample as a random variable. If all elements of the population have equal chances to get into the sample during the next test (randomness of the sample), then the formula for the joint probability of this value is well known. At the same time, this function depends on the estimated volume of the population as its parameter. Substituting real data into the formula and maximizing it by this parameter, we get the most “plausible” estimate for the estimated value [3]. In this paper, we are based on data on the frequency of mentions of personalities in acts. And to solve the problem of estimating the volume of the entire population, an approach in mathematical statistics that has been intensively developing since the mid-1960s, associated with random placements, is involved. In accordance with this approach, we will operate with a set of statistics that represent just the frequency of occurrence of the observed sample elements. Using these statistics, we will construct a linear estimate, which turns out to be unbiased for the estimated value of the total number of merchant customers. II. Assessment task Denote by n – the sample size, and by N – the volume of the entire population, which we have to evaluate. Since the sample is extracted from the aggregate according to the random selection scheme with a return, there may be duplicate elements in it. Denote by ? r the number of observed elements, each of which was repeated exactly r times, r=1,..,n. Our task is to use the information contained in a set of statistics (? 1, ? 2,..,? n) to estimate an unknown quantity N. It is not difficult to verify that all these statistics are related by the ratio ? 1+ 2 ? 2 +3 ? 3 +..+ n ? n =n. Therefore, one of the statistics can be expressed through all the others. With this observation in mind, we will limit ourselves in the future to considering the shortened set (? 2,..,? n). Following the logic of [4], we will look for a solution in the class of linear unbiased estimates, and we will evaluate not N, but the inverse of 1/N. That is, the desired estimate is a linear combination of statistics (µ2,..,µn), and its mathematical expectation must exactly coincide with 1/N: is a linear combination of statistics (µ2,..,µn), and its mathematical expectation must exactly coincide with 1/N:
  In the formula (1), the summation operation by the index r running through the values from 2 to n is denoted by ?, and in (2), the mathematical expectation (average value) of a random variable is denoted by E.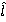 It is necessary to point out the difference between this approach and the one that we demonstrated earlier. If in [3] the desired value N is determined from the maximum likelihood principle, that is, from the formula for its most probable value (mode), then in this article we operate in terms of mathematical expectation. Fashion, like mathematical expectation, are important characteristics of a random variable. In the general case (when the distribution is asymmetric) they do not coincide with each other, which is demonstrated in Fig.1, where the value of the mathematical expectation will be shifted relative to the mode (to the left): 
Fig. 1Fashion and mat.expectation of a discrete random variable (indicated by lettersM and E respectively) Thus, the involvement of these two approaches allows you to independently refine the range of possible values of the desired value. As can be seen from formulas (1)-(2), to calculate the coefficients l r, it is necessary to find the mathematical expectation of random variables ? r, r = 2,..,n. An elegant derivation of the formula for E ? r is given in [5]. To begin with, let's move from the initial choice with a return to the equivalent scheme of equally probable placement, in which n particles are placed independently of each other by N cells. Denote by ? ir an indicator that takes a single value if exactly r particles hit the i-th cell, and zero otherwise. In this case, the statistics of ? r can be represented as the sum of the corresponding indicators:  Then, taking into account the independence of the indicators from each other, we get  where P(? ir = 1) denotes the probability that the corresponding indicator will take a single value. If the probability of one particle hitting a fixed cell is 1/N, then r particles will hit it with probability (1/N)r. Hence it is not difficult to conclude that the probability of n-r particles falling into the remaining N-1 The number of cells will be ((N-1)/N)n-r=(1-1/N)n-r.
The number of possible ways to select r particles from n is known and is determined by the formula of the number of combinations From here, applying the theorem on the addition of probabilities, we come to the formula for the mathematical expectation of random variables ? r: 
Then, taking into account (1), the formula (2) for evaluation is presented in the following form: 
Multiply both parts of the resulting equation by the value N. By reducing the same multipliers in its left part, we get 
Applying the Newton binomial (see Appendix 1), we find from (3) the formula for the estimation coefficients, first obtained in [4]: 
Returning to (1), from here we finally get  The resulting formula allows us to proceed to the task of estimating the number of acts of Predon. III. Numerical modeling The preliminary stage for modeling the number is the identification of the names given in the acts. This procedure is complicated by the fact that some personalities appear under several, albeit rather similar, names, such as, for example, Ogerius [1, p.89], Ogerinus [1, p.91]. Moreover, the same person can act in acts and in different roles. Thus, the same Ogerius in some contracts of the commission acts as a tractator (accomendatarius, that is, a partner receiving funds from the commendator to conduct trade in an established place), in other contracts – as a witness, and in the acts of the will – as a recipient of the will. In such cases, only an additional indication of the profession or position (for example, placerius peliparius) allows them to be identified as one person [6]. In total, 447 personalities were identified in the acts, which were mentioned 866 times (women are also included here). At the same time, slaves, as objects of purchase/sale transactions, were not taken into consideration. Below is a graph of the frequency of mentioning individual personalities, ordered by non-decreasing: 
Fig. 2A ranked number of mentions of personalities in the acts of Predono 1281 Thus, the first rank (the maximum frequency is 68 mentions) corresponds to one person – the notary Guglielmo Gandulfi, who was almost constantly involved as a witness to the contract. All other persons are mentioned significantly fewer times. So, exactly once (the highest rank) 318 persons are mentioned. For more clarity, the relevant statistics are given in the following table: Table 1. Distribution of the number of personalities by frequency of mention 
Note: ? r is the number of personalities mentioned exactly r times.
A simple visual observation of the frequency of mention does not allow us to conclude that the sampling data is random, which is confirmed by the consideration of the criterion ?2 (chi-square). To ensure the correctness of the evaluation procedure, in our previous article [3] it is proposed to move from the initial to the consideration of a truncated sample, in which rare data corresponding to high frequencies of occurrence are excluded. So, if we remove from consideration the first 10 personalities in frequency (with frequencies from 68 to 9), then with a significance level of 0.1, this sample can already be considered random. After removing these 10 elements, the sample size n is reduced from 866 to 700, and the number of different elements i in it becomes 437, respectively (instead of the previous 447). At the same time, the value ?2 of statistics calculated by the formula is 448.6857, which is less than the corresponding quantile equal to 475.2005 [7, p. 577]. All this allows us to proceed to the estimation of the volume N of the general population. Referring to the formula (4), we get N = 439. This figure is lower than the estimate based on the same data obtained in [3] (N=688). Note that approximately the same estimate for the number (N=645-650) is given by the approach of A.L. Ponomarev, based on a modification of the empirical Zipf law [8,9]. Such a discrepancy (439 against 688 people) requires additional investigation. IV. Comparison of simulation results First of all, let's try to move in the direction of further truncation of the sample. So, after removing another 15 personalities from consideration (with frequencies from 8 to 6), the sample size is reduced from 700 to 600, and the number of different elements i in it decreases, respectively, from 437 to 422. The application of the first approach (from [3]) gives an estimate of 823 people, and the second (from this article) – 660 people. It is convenient to summarize the results of further application of a similar procedure in the following table: Table 2. Estimation of the size of the community by the distribution of the number of personalities by frequency of mention 
Note: The method from [3] is indicated by "method I", and the method from this article is indicated by "method II". This table also includes the results of A.L. Ponomarev's modeling from the articles [8,9]. The analysis of Table 2 shows that as the sample size is truncated, the estimates of both methods (method I and method II) tend to increase and converge their values, up to the intersection of the corresponding graphs, which is conveniently demonstrated in the following figure: 
Fig. 3 Estimation of the size of the entire community according to methods I and II As for method II, we point out the similarity of its results with a sample size n of 600 (with the number of different elements i =422) with the results of A.L. Ponomarev (with the number of different elements i =507). In the situation of choosing between method I and method II, it is useful to compare the results of both methods on some simple and unambiguous examples, abstracting from the specifics of the problem being solved. Example 1. Let the general population consist of one single element (N=1). This element is extracted from it by a return selection a hundred times n (n=100). It is clear that all elements are the same, and the number of different elements is equal to one (i=1). Let's consider the evaluation results that both methods will give. Recall that the first method (method I) is based on maximizing the likelihood function 
where by  denotes the number of combinations from N to i: denotes the number of combinations from N to i: .If we substitute here the specific values of i and n, it is not difficult to calculate that .If we substitute here the specific values of i and n, it is not difficult to calculate that . This function reaches its maximum with a minimum value of N equal to one, which coincides with its true value. . This function reaches its maximum with a minimum value of N equal to one, which coincides with its true value. Now we get an estimate for N according to the second method (method II). In his terms, the number of elements repeated exactly r=n times is equal to one (? r=1). Substituting these values into formula (4), we get 
that is, even here the approximate estimate coincides with the true one: N= 1. Example 2. Let's complicate the previous example a little. Now let the general population consist of ten elements (N=10). One element is extracted from it by the return selection, as before, 100 times (n=100). At the same time, all these ten elements are present in the formed sample, moreover, in equal quantities. In our terms, this is equivalent to i=10, r=10 and ? r=10. It is not difficult to verify that the application of the method with maximization of the likelihood function (method I) gives an accurate estimate of N=10. Now substitute the specific values in formula (4) for the second method: 
from where we get an approximate estimate for N=11. So, it can be stated that the second method in some cases (and quite simple ones) gives less accurate estimates than the first method. This fact can be explained, in our opinion, by the fact that the second method estimates not the value of N itself, but the inverse of it . In the case when it is small enough, the reversed value behaves very unstable due to rounding errors. Apparently, this also happens in our particular case. . In the case when it is small enough, the reversed value behaves very unstable due to rounding errors. Apparently, this also happens in our particular case. To demonstrate this statement, let us return again to the case when the first ten elements in frequency of occurrence (n=700, i=437) were removed from the initial sample. Substituting specific values into formula (4) for gives a value equal to 0.002329859. To estimate the value of N, we need, of course, to reverse the last value, obtaining the value 429. How unstable this estimate is can be judged by the fact that if you round the value up to one thousandth (up to 0.002), then the opposite value will be 500 (instead of 429). That is, a negligible change leads to a change in the estimated value by tens of units. Summarizing the above, we can say that the use of the second method should be treated with caution, and in this particular case, give preference to the estimate obtained by the first method, that is, to estimate the number of the merchant community of Pera at the end of the XIII century at about 688 people. At the same time, the second method tested in this article may be useful for similar studies on a different source base. Appendix 1. To find the coefficients l r from equation (3), we use the Newton binomial formula: 
where a and b are arbitrary, and l, m are natural numbers. Let 's put  Given that in this case a+b=1, the Newton binomial is rewritten as:

Next, in the last formula, we will replace the summation variable: r = l+2. Thus, with an initial value of l=0 the new variable is r=2, and when the final value is l=n-2, the variable is r=n.With this in mind, the Newton binomial is finally transformed as  Now equate this formula and formula (3), we have  Obviously, this equality holds only if all the corresponding terms are equal in the right and left parts of it, that is Thus, we come to the formula for the coefficients
References
1. Actes des notaires genoise de Pera et de Caffa de la fin de la treizieme siècle (1281-1290)/publies par Bratianu G.I. – Bucarest, 1927.– 381 P.;
2. Karpov S.P. Akty genuezskih notariev, sostavlennye v Kaffe i drugih gorodah Prichernomor'ya v XIV–XV vv.// Prichernomor'e v Srednie veka. – Spb., 2018.– vyp. X.– 760 S.;
3. Shpirko S.V. Kogo net, togo i soschitat' (ili eshche raz k voprosu o chislennosti genuezskih kupcov v Vizantii) // Istoricheskaya informatika. – 2021. – № 2. – S. 79-87;
4. Ivchenko G.I., Timonina E.E. Ob ocenivanii pri vybore iz konechnoj sovokupnosti// Matematicheskie zametki. – 1980. – Tom 28. – vypusk 4. – S. 623-633;
5. Kolchin V.F., Sevast'yanov B.A., CHistyakov V.P. Sluchajnye razmeshcheniya. – M.,1976. – 225 C.;
6. Karpov S.P., Il'yashenko V.A. Opyt postroeniya relyacionnoj bazy prosopografii ital'yanskih faktorij Prichernomor'ya (XIII—XV vv.) // Istoricheskaya informatika. – 2021. – № 3. – S. 38-48;
7. Ivchenko G.I., Medvedev Yu.I. Vvedenie v matematicheskuyu statistiku.– M., 2009. – 600 S.;
8. Ponomarev A.L. Kogo net, togo ne soschitat'? ili skol'ko v Vizantii bylo znati i kupcov// Matematicheskie modeli istoricheskih processov. — M., 1996. — S. 236—244;
9. Ponomarev A.L. Etnicheskij i konfessional'nyj sostav naseleniya Kaffy v konce XIV v. po dannym Massarij (o metodike obrabotki materiala)// Byzantium. Identity, Image, Influence: Extracts. XIX International Congress of Byzantine Studies. University of Copenhagen, 18-24 August, 1996: Abstracts of Communications. — Copenhagen, 1996. — P. 3116.
Peer Review
Peer reviewers' evaluations remain confidential and are not disclosed to the public. Only external reviews, authorized for publication by the article's author(s), are made public. Typically, these final reviews are conducted after the manuscript's revision. Adhering to our double-blind review policy, the reviewer's identity is kept confidential.
The list of publisher reviewers can be found here.
Review of the article "Once again on the issue of estimating the number of Genoese merchants in Byzantium at the end of the XIII century using methods of mathematical statistics" This article, submitted to the journal "Historical Informatics", has a pronounced methodological character. It is devoted to the testing of one of the methods of mathematical statistics to solve the problem of missing data on the number of Genoese merchants in Constantinople at the end of the XIII century. For the first time, this task was set by A.L. Ponomarev, who proposed using the data of 149 notarial acts drawn up in 1281 and published in 1927. These acts contain the names of participants in commercial transactions, who could be contractors, witnesses, other participants, and be present repeatedly in the forms of documents. In total, 447 personalities were identified in the acts, which were mentioned 866 times. In the article, based on the repeated sampling already introduced into scientific circulation and the construction of a discrete distribution of the frequency of occurrence of the number of mentions of the same persons, an estimate of the mathematical expectation of the volume of the general population is calculated. This result is compared by the author with the previously obtained estimate of another statistical characteristic – fashion. To work with a theoretically random sample, the author uses a method in which rare data corresponding to high frequencies of occurrence are excluded (this method is often used to correct the so-called "edge effects" in hyperbolic distributions, such as Zipf's law, used by A.L. Ponomarev). However, it is unclear why the distribution illustrated by the graph in Fig. 2 is called uniform by the author (reservation?). Of methodological interest is Table 2, which shows the effect of the level of adjustment of "edge effects" on the sample size and, accordingly, on the estimation of an unknown volume of the general population, which gives the author reason to conclude that the results of the two approaches he used are converging (Fig. 3). An additional consideration is the influence of rounding errors associated with the proposed Calculations are not of the volume of the general population itself, but of the inverse value, an additional argument for which were illustrative examples. Speaking about the article as a whole, it should be noted that the text lacks a meaningful component: the modeling task is not clearly formulated enough – estimating the volume of the general population based on the available sample, the conclusion is too short, consisting in fact of one phrase. In the opinion of the reviewer, more attention should be paid to the comparative analysis of the methodology of this article and the work mentioned in the text by S.V. Shpirko "Who is not there, and count (or once again to the question of the number of Genoese merchants in Byzantium)" (Historical Informatics. - 2021. – No. 2), especially since the method proposed in this article (estimation of mathematical expectation), in the opinion of the author himself, gives less convincing results compared to the previous article, which evaluates another statistical indicator – fashion. And, of course, a comparison of the results of the proposed methodology with the results of the well-known works of A.L. Ponomarev deserves more attention, since this can provide useful methodological recommendations regarding the choice of a particular mathematical method, moreover, on the same source base. In particular, in the table. 2 we see a fairly large similarity of the author's results in this article (660 non-repeating personalities for a repeat sample of 600) with the results of one of A.L. Ponomarev's works (645-650), whereas for a repeat sample of 432, the author receives 1,558 non-repeating personalities according to his previous method, which is close to the results of another work by A.L. Ponomarev (1586). It seems that a more thorough and meaningful interpretation is needed here. At the same time, the article is overloaded with detailed mathematical calculations, which it is desirable to transfer to the application, since it may be of interest only to a small part of readers with proper training. We add that for a prepared reader, questions will arise about the uninformative Figure 1, which must either be commented on in more detail or completely deleted (without prejudice to the content). Note also that in this article (see Table. 2), as in the article referred to by the author of this article, apparently, the links to two articles by A.L. Ponomarev are mixed up: in the article "Who is not there, cannot be counted? or how many nobles and merchants there were in Byzantium" (Mathematical models of historical processes. – M., 1996), A.L. Ponomarev does not have the estimate of the volume of the general population (645-650) that the author gives, apparently, this estimate is given in the work "The number of merchants and the volume of trade of the Genoese colony in Pera in 1281 (according to the Gabriele de Predono Cartulary)" (XVIII International Congress of Byzantinists. Summary of messages. Lomonosov Moscow State University August 8-15, 1991 – Moscow, 1991). It is desirable to include the publication in the bibliography: Karpov S.P., Ilyashenko V.A. The experience of building a relational database of prosopography of Italian Black Sea trading posts (XIII – XV centuries) // Historical Informatics. - 2021. – No. 3. The author should also pay more attention to the design of the work. First, the bibliographic list must be brought into line with GOST, especially in terms of prescribed punctuation marks and spaces. Secondly, formulas are not always successfully "embedded" in the text, but are located above the line. Thirdly, in the structure of the work, two sections (Numerical modeling and the Estimation Problem) have the same number – II. Finally, it is necessary to check the spelling: for example, to correct the separate spelling (not difficult, not stable) to merge. Nevertheless, from a methodological point of view, the article is of interest to authors dealing with quantitative history, and can be recommended for publication taking into account the comments made. Comments of the editor-in-chief dated 02/01/2022: "The author has fully taken into account the comments of the reviewers and corrected the article. The revised article is recommended for publication"
|

 Eng
Eng






































