Cybernetics and programming
Reference:
Revnivykh, A.V., Velizhanin, A.S. (2018). The method of automated research of the structure of disassembled representation of software code with a buffer overflow vulnerability using the matrix approach. Cybernetics and programming, 6, 11–30. https://doi.org/10.25136/2644-5522.2018.6.28288
The method of automated research of the structure of disassembled representation of software code with a buffer overflow vulnerability using the matrix approach
Revnivykh Aleksandr Vladimirovich
PhD in Technical Science
Associate Professor, Department of Information Security, Novosibirsk State University of Economics and Management
630099, Russia, Novosibirskaya oblast', g. Novosibirsk, ul. Kamenskaya, 56

|
al.revnivykh@mail.ru
|
|
 |
Other publications by this author
|
|
|
Velizhanin Anatolii Sergeevich
Specialist, Tyumen Industrial University
625000, Russia, Tyumenskaya oblast', g. Tyumen', ul. Volodarskogo, 38
|
|
anatoliy.velizhanin@gmail.com
|
|
|
Other publications by this author
|
|
|
DOI: 10.25136/2644-5522.2018.6.28288
Received:
06-12-2018
Published:
13-12-2018
Abstract:
The subject of the research is the optimization algorithms for automated dependency search on disassembled code. The object of the research is the dependent code blocks on the x64 architecture of Intel processors manufactured by the company and listings obtained as a result of reverse engineering software by compilers with different settings in Windows and Linux.Purpose of the study. The purpose of the study is to consider the possibility of using mathematical matrices to build a machine code map, and also to review possible problems for automatic analysis, to search for the paths of information flows. Research methods. We used the Visual C ++ compiler. We consider the architecture in which the transfer of information can be carried out in the following ways: register-memory, memory-register, register-register. For the analysis, the method of forming the list of functions called up to the potentially dangerous block of code under investigation, chosen for each considered path to the block under study, was chosen. Methods for implementing the matrix approach are described and developed. Novelty and key findings. Mathematical matrix method can be used to build a machine code map. However, determining the reachability paths of individual code blocks may require a significant amount of resources. In addition, the machine code can be exposed to packers and obfuscators, which also introduces additional complexity. A number of potentially dangerous functions of the standard library of the C / C ++ programming language were identified.
Keywords:
Information security, Vulnerabilities, Code analysis, Disassembling, Buffer overflow, Mathematical Matrix Method, Code compilers, Code Packers, Code obfuscators, Functions List
This article written in Russian. You can find original text of the article here
.
1. Введение
Дизассемблированные листинги, полученные в результате реверс-инжиниринга программного обеспечения, собранного различными компиляторами в Windows и Linux, могут быть в значительной степени различны. Их объемы могут значительно превышать десятки тысяч страниц печатного текста для современных крупных программных решений. Это значительно усложняет анализ функционирования программного обеспечения без использования исходного кода. В настоящее время имеются некоторые алгоритмы автоматизированного поиска зависимостей на дизассемблированном коде, применяемые во множестве дизассемблеров. Например, IDA Pro обладает функционалом построения зависимостей по функциям, обнаруженным в дизассемблируемом программном модуле, и строит их графическое представление.
2 Подход к анализу зависимостей
Зависимыми блоками кода мы будем считать те, что, получая управление, получают также определенную информацию из вызывающего блока кода или ранее, либо указатель на нее. Таким образом, при вызове дочерней функции, принимающей, например, 2 аргумента и возвращающей указатель на сформированный ею объект как результат, мы имеем 2 взаимозависимых крупных блока кода. Следует отметить, что, например, в архитектуре Intel для x86 и x64 процессоров при вызове функции передается (или точнее сказать сохраняется в стеке) адрес возврата в вызывающую процедуру, что, по сути, так же можно расценивать как передачу параметра в функцию, который будет задействован инструкцией RET или подобными. Подобного рода разбиение дизассемблированного листинга на функции выполняют некоторые дизассемблеры (например, IDA Pro) для повышения удобства исследования программного модуля при анализе больших по объему кода листингов.
Однако разрабатывая алгоритмы и методы автоматизированного анализа, возможно, является правильным использование максимально мелкого дробления дизассемблированного кода, разбивая его на блоки с линейным ходом выполнения, а не на функции. Причиной данного предположения является то, что максимально мелкое дробление кода может позволить построить более детальное представление структуры листинга. Конечно, для анализа человеком значительное усложнение представления структуры кода (по причине, в ряде случаев, значительно повышенной дробности) не является удобным. Тем не менее, для машинного анализа данный фактор, вероятно, не является существенным недостатком, хотя приведет к повышенному расходу ресурсов компьютерной системы, используемой для анализа. В вышеизложенном примере крупным блоком будет являться родительская функция, а вторым — дочерняя. Далее мы продолжим исследования для х64 архитектуры процессоров производства корпорации «Intel».
В источнике [1] компания Microsoft приводит общие сведения о реализации вызовов для x64 в операционной системе (далее – «Win64»). Дополнительную информацию о программировании на языке Assembler и особенностях работы программ для Win64 можно получить из источника [2], а также ряд дополнительных полезных сведений находится в официальной документации на процессор.
Для рассматриваемой нами архитектуры передача информации может быть осуществлена следующими способами: регистр-память, память-регистр, регистр-регистр. Регистры процессора могут хранить как непосредственно соответствующее значение, так и адрес в оперативной памяти (указатель), по которому расположена информация. Таким образом, для проведения автоматизированного анализа, необходимо отслеживать операции, выполняемые инструкциями, которые манипулируют информацией или указателями на нее.
Отметим, что одними из наиболее важных при поиске уязвимостей являются пути, проходящие через потенциально опасные функции. Потенциально опасными будем считать те функции, которые выполняют вызовы стандартной библиотеки или любых других API-функций, при использовании которых программисты часто совершают ошибки (примерном простейшей ошибки может быть отсутствие контроля над размерностью массивов при вызове функции strcpy стандартной библиотеки языка программирования C/C++) [7-24].
Одним из методов, который мог бы частично решить проблему анализа дизассемблированного кода, является формирование списка функций, вызываемых до исследуемого потенциально опасного блока кода, сформированный для каждого рассматриваемого пути к исследуемому блоку.
Такой анализ, несомненно, имеет не очень высокую степень точности, но позволяет сделать ряд предположений, которые могут использоваться для более детального изучения и оценки перспективности исследования заданного пути в дизассемблированном листинге. Приведем пример, иллюстрирующий данное утверждение. В листинге 1 изображен код, копирующий строку из аргумента командной строки в символьный буфер с предварительной проверкой длины.
Листинг 1
#include
#include
#define MAX_PARAMLENGTH 10
using namespace std;
int main(int argc, char *argv[])
{
if (argc < 2)
{
cout << "Start by: <programm_name.exe> <string_parameter>n";
return -1;
}
if (strlen(argv[1]) > MAX_PARAMLENGTH)
{
cout << "parameter length must be less than " << MAX_PARAMLENGTH;
return -1;
}
char arr[MAX_PARAMLENGTH + 1];
strcpy(arr, argv[1]);
cout << arr << endl;
return 0;
}
Сборка проводилась в интегрированной среде разработки «Microsoft Visual Studio 2012 Ultimate» в режиме «Debug x64» в операционной системе «Microsoft Windows 8 Professional x64». Для данной программы мы имеем дизассемблированный код, изображенный в листинге 2.
Листинг 2
main:
0000000140001400: 48 89 54 24 10 mov qword ptr [rsp+10h],rdx
0000000140001405: 89 4C 24 08 mov dword ptr [rsp+8],ecx
0000000140001409: 57 push rdi
000000014000140A: 48 83 EC 60 sub rsp,60h
000000014000140E: 48 8B FC mov rdi,rsp
0000000140001411: B9 18 00 00 00 mov ecx,18h
000000014000141B: F3 AB rep stos dword ptr [rdi]
000000014000141D: 8B 4C 24 70 mov ecx,dword ptr [rsp+70h]
0000000140001421: 48 8B 05 F8 EC 00 mov rax,qword ptr [__security_cookie]
0000000140001428: 48 33 C4 xor rax,rsp
000000014000142B: 48 89 44 24 50 mov qword ptr [rsp+50h],rax
0000000140001430: 83 7C 24 70 02 cmp dword ptr [rsp+70h],2
0000000140001435: 7D 1D jge 0000000140001454
0000000140001437: 48 8D 15 32 B7 00 lea rdx,[14000CB70h]
000000014000143E: 48 8B 0D 83 12 01 mov rcx,qword ptr [__imp_?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A]
0000000140001445: E8 C4 FC FF FF call @ILT+265(??$?6U?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@PEBD@Z)
000000014000144A: B8 FF FF FF FF mov eax,0FFFFFFFFh
000000014000144F: E9 84 00 00 00 jmp 00000001400014D8
0000000140001454: B8 08 00 00 00 mov eax,8
0000000140001459: 48 6B C0 01 imul rax,rax,1
000000014000145D: 48 8B 4C 24 78 mov rcx,qword ptr [rsp+78h]
0000000140001462: 48 8B 0C 01 mov rcx,qword ptr [rcx+rax]
0000000140001466: E8 35 30 00 00 call strlen
000000014000146B: 48 83 F8 0A cmp rax,0Ah
000000014000146F: 76 28 jbe 0000000140001499
0000000140001471: 48 8D 15 30 B7 00 lea rdx,[14000CBA8h]
0000000140001478: 48 8B 0D 49 12 01 mov rcx,qword ptr [__imp_?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A]
000000014000147F: E8 8A FC FF FF call @ILT+265(??$?6U?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@PEBD@Z)
0000000140001484: BA 0A 00 00 00 mov edx,0Ah
0000000140001489: 48 8B C8 mov rcx,rax
000000014000148C: FF 15 76 11 01 00 call qword ptr [__imp_??6?$basic_ostream@DU?$char_traits@D@std@@@std@@QEAAAEAV01@H@Z]
0000000140001492: B8 FF FF FF FF mov eax,0FFFFFFFFh
0000000140001497: EB 3F jmp 00000001400014D8
0000000140001499: B8 08 00 00 00 mov eax,8
000000014000149E: 48 6B C0 01 imul rax,rax,1
00000001400014A2: 48 8B 4C 24 78 mov rcx,qword ptr [rsp+78h]
00000001400014A7: 48 8B 14 01 mov rdx,qword ptr [rcx+rax]
00000001400014AB: 48 8D 4C 24 28 lea rcx,[rsp+28h]
00000001400014B0: E8 E5 2F 00 00 call strcpy
00000001400014B5: 48 8D 54 24 28 lea rdx,[rsp+28h]
00000001400014BA: 48 8B 0D 07 12 01 mov rcx,qword ptr [__imp_?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A]
00000001400014C1: E8 48 FC FF FF call @ILT+265(??$?6U?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@PEBD@Z)
00000001400014C6: 48 8B 15 33 11 01 mov rdx,qword ptr [__imp_?endl@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@1@AEAV21@@Z]
00000001400014CD: 48 8B C8 mov rcx,rax
00000001400014D0: FF 15 3A 11 01 00 call qword ptr [__imp_??6?$basic_ostream@DU?$char_traits@D@std@@@std@@QEAAAEAV01@P6AAEAV01@AEAV01@@Z@Z]
00000001400014D6: 33 C0 xor eax,eax
00000001400014D8: 48 8B F8 mov rdi,rax
00000001400014E5: E8 16 30 00 00 call _RTC_CheckStackVars
00000001400014EA: 48 8B C7 mov rax,rdi
00000001400014ED: 48 8B 4C 24 50 mov rcx,qword ptr [rsp+50h]
00000001400014F5: E8 66 33 00 00 call __security_check_cookie
00000001400014FA: 48 83 C4 60 add rsp,60h
00000001400014FE: 5F pop rdi
00000001400014FF: C3 ret
В вышеприведенных листингах мы намеренно приводим полный код функции «main» несмотря на его несколько большие объемы. Это позволит в дальнейшем более удобно сравнивать результаты предлагаемого метода с приведенным кодом.
В листинге 1 производится предварительная проверка длины строки первого аргумента в командной строке. Затем, в случае соответствия заданному ограничению, производится копирование в массив символов фиксированной длины.
Для данного листинга, применяя матричный метод, мы получим следующую матрицу смежности (отсчет номеров блоков начинается с нуля). Предлагаемый вариант реализации матричного подхода предполагает под собой разбиение дизассемблированного листинга на элементарные блоки кода, с линейным ходом выполнения. Последней инструкцией каждого блока (кроме последнего) обязательно является инструкция условного или безусловного перехода. Последний блок кода может заканчиваться любой инструкцией.
-Matrix- #0
-Block- #0 Start=0x40001400 End=0x40001435
-Block- #1 Start=0x40001437 End=0x40001445
-Block- #2 Start=0x4000144A End=0x4000144F
-Block- #3 Start=0x40001454 End=0x40001466
-Block- #4 Start=0x4000146B End=0x4000146F
-Block- #5 Start=0x40001471 End=0x4000147F
-Block- #6 Start=0x40001484 End=0x4000148C
-Block- #7 Start=0x40001492 End=0x40001497
-Block- #8 Start=0x40001499 End=0x400014B0
-Block- #9 Start=0x400014B5 End=0x400014C1
-Block- #10 Start=0x400014C6 End=0x400014D0
-Block- #11 Start=0x400014D6 End=0x400014E5
-Block- #12 Start=0x400014EA End=0x400014F5
-Block- #13 Start=0x400014FA End=0x400014FF
|
|
(0)
|
(1)
|
(2)
|
(3)
|
(4)
|
(5)
|
(6)
|
(7)
|
(8)
|
(9)
|
(10)
|
(11)
|
(12)
|
(13)
|
|
(0)
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(1)
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(2)
|
0
|
2
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(3)
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(4)
|
0
|
0
|
0
|
2
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(5)
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(6)
|
0
|
0
|
0
|
0
|
0
|
2
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(7)
|
0
|
0
|
0
|
0
|
0
|
0
|
2
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(8)
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(9)
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
2
|
0
|
0
|
0
|
0
|
0
|
|
(10)
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
2
|
0
|
0
|
0
|
0
|
|
(11)
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
2
|
0
|
0
|
0
|
|
(12)
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
2
|
0
|
0
|
|
(13)
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
2
|
0
|
Таблица 1
В таблице 1 значение 0 соответствует отсутствию пути, 1 - наличию пути, 2 – вероятному наличию пути (предполагаем, что вызов функции call, лежащей за пределами листинга, вернет управление на следующую инструкцию, как должно быть согласно стандарту), 3 – переход (не call) по адресу вне границ листинга, управление может быть возвращено в любую позицию (в данном листинге такого типа перехода не встречалось).
Приведенная к листингу 1 таблица 1 иллюстрирует собой матрицу смежности для рассматриваемой нами функции «main». В данной таблице синим цветом выделена потенциально опасная функция стандартной библиотеки языка программирования С/С++. Как мы видим из матрицы, вызов данной функции находится непосредственно на стыке 8-го и 9-го линейных блоков кода и принадлежит 8-му блоку. Желтым цветом в таблице 1 отмечены блоки, через которые необходимо пройти для достижения интересующего нас 8-го блока. На пути следования потока управления, согласно полученной матрице, в блоке 3 мы имеем внешний, по отношению к текущему листингу, вызов.
Обратившись к листингу 2, мы видим, что в данном блоке производится вызов функции стандартной библиотеки языка программирования С/С++ strlen, осуществляющей замер длины строки, переданной ей в качестве параметра. Наличие подобного вызова уменьшает вероятность уязвимости, однако не исключает ее совсем, поскольку мы не можем быть уверены (в случае исследования реального кода проектов, исходных кодов которых мы предварительно не изучали), что контроль размерности производится верно. Кроме того, когда мы обнаруживаем в коде контроль выхода за границы массива (это же касается и проверки длины строки, поскольку строка фактически является массивом символов) нам стоит убедиться, что сравнение проводится корректно. В частности, в сравнении может быть уязвимость по причине неверного сравнения signed и not-signed значений. Помимо прочего нам необходимо убедиться, что контроль размерности происходит именно для символьного массива-источника, из которого происходит копирование в размещенный в стеке массив-приемник. Для этого необходим алгоритм, позволяющий обнаруживать механизмы и строить пути передачи информации.
Рассматривая вопрос анализа зависимостей, мы можем обнаружить, что значительная часть информации по данной теме ориентирована на использование в оптимизирующих компиляторах. Безусловно, вопрос обнаружения зависимостей является одним из ключевых не только в их алгоритмах оптимизации, но и в автоматическом распараллеливании программ. Отметим, что в данном контексте имеются в виду именно высокоуровневые языки программирования. Материал по вопросу поиска зависимостей по данным можно получить, например, из источников [3-5]. Информация, приведенная в данных источниках, иллюстрируется на примерах DO-циклов.
Однако методы, предложенные в ресурсах [3-5] приводились для определенной модели программы и предназначены для соответствующих задач. В реальных программных системах циклы могут хранить довольно сложные внутренние условия выходов и модификации информации (в том числе формирующей условия выхода). Кроме того, нашей задачей является поиск путей следования информационных потоков, а не распараллеливание и оптимизация кода перед сборкой исполняемого файла. Таким образом, мы получаем несколько отличную задачу.
Вернемся к построению путей. Предложенная в таблице 1 матрица иллюстрировала взаимосвязи между линейными блоками кода программы и предоставляла более широкую информацию, нежели обычные матрицы смежности. Предполагается, что данную информацию можно расширить для большей информативности взаимосвязей и особенностей блоков кода. Обычная матрица смежности иллюстрирует лишь наличие связи между данными блоками. Для обнаружения достижимости заданной точки данная расширенная информация не является необходимой. Таким образом, мы можем значения aij > 0 матрицы из таблицы 1 приравнять к 1. Исключением в общем случае может быть лишь код 3, предназначенный для отображения перехода по адресу, лежащему за пределами листинга и, возможно, возвращающему управление по неизвестному заранее адресу, который, не исключено, может вообще находиться вне диапазона адресов данного листинга. Тогда мы получим простую матрицу смежности. Данная матрица достижимости позволит сделать первоначальный вывод о потенциальной возможности влияния информацией, поданной на определенную точку входа в процесс, на потенциально уязвимую функцию.
Однако дополнительно проведенные исследования показали, что, учитывая столь мелкое дробление кода на линейные блоки, построение матрицы достижимости для реальных проектов может быть затруднительной задачей в связи со значительными затратами времени на возведение крупных матриц в высокие степени. Таким образом, в ряде случаев более эффективным может быть вариант систематического обхода вершин графа, построенного на основе анализа взаимосвязей элементарных блоков кода, (возможно, используя для этого первоначальную матрицу смежности) на указанную заранее глубину. Ограничение глубины и выборочный проход в ходе анализа по отдельным блокам кода снижает количество анализируемых блоков кода и уменьшает необходимое число операций, что позволяет значительно сократить время анализа.
Проанализировав в совокупности точки входа в процесс и возможность их влияния на отдельные функции программы, мы можем сделать первоначальный вывод о перспективных векторах исследования программного модуля в поисках уязвимостей.
Различные режимы компиляции могут привести к развертыванию отдельных вызовов внутрь собираемого модуля (например, «inline» функции в языке программирования C/C++, а также не «inline» функции при установленной оптимизации). Таким образом, часть вызовов (инструкций call) может быть удалена из результирующего файла и заменена на соответствующий код, выполняющий определенную задачу. Для распознавания подобных случаев может быть использована, например, технология F.L.I.R.T. (Fast Library Identification and Recognition Technology), предлагаемая в программном продукте IDA Pro [6]. В нашей работе мы будем использовать сборки без развернутых в них функций, поскольку основной нашей задачей является определение путей между точками входа информации в процесс и потенциально уязвимыми функциями.
Проведем эксперимент. Для повышения наглядности реализации задачи несколько модифицируем листинг 1. Полученный результат приведен в листинге 3. В данном листинге так же приведен полный код для повышения удобства сравнения нового варианта исходного кода с представленным в листинге 1.
Листинг 3
#include
#include
#define MAX_PARAMLENGTH 10
using namespace std;
int main(int argc, char *argv[])
{
if (argc < 2)
{
cout << "Start by: <programm_name.exe> <string_parameter>n";
return -1;
}
char arr0[MAX_PARAMLENGTH + 1];
char arr[MAX_PARAMLENGTH + 1];
char arr1[MAX_PARAMLENGTH + 1];
strcpy(arr, argv[1]);
cout << arr << endl;
return 0;
}
Приведенный в листинге 3 исходных код содержит в себе простейшую уязвимость. При записи в переменную «arr» слишком длинной строки, значение из «argv[1]» перезаписывает память за пределами массива-приемника, и искажает кадр стека. Кроме того, массивы «arr*» не инициализированы 0-значениями. Это означает, что в конце массива символов не обязательно может присутствовать 0-символ, означающий конец строки. В ряде случаев это может вызвать уязвимость. Результатом данного эксперимента являлось аварийное завершение программы (рис. 1).
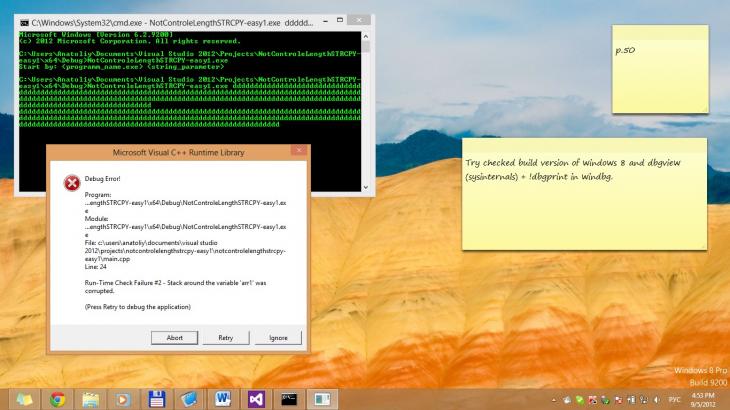
Рис. 1. Аварийное завершение работы программы
Получим дизассемблированный листинг данной функции и преобразуем его в удобную для автоматизированного анализа нашим методом форму. Результат изображен в листинге 4. Листинг 4 так же содержит полный код функции «main» для удобства сравнения с дизассемблированным представлением данной функции, приведенном в листинге 2, а также для проведения анализа построенной матрицы зависимостей в таблице 2.
Листинг 4
0000000140001400: 48 89 54 24 10 mov qword ptr [rsp+10h],rdx
0000000140001405: 89 4C 24 08 mov dword ptr [rsp+8],ecx
0000000140001409: 57 push rdi
000000014000140A: 48 81 EC C0 00 00 sub rsp,0C0h
0000000140001411: 48 8B FC mov rdi,rsp
0000000140001414: B9 30 00 00 00 mov ecx,30h
000000014000141E: F3 AB rep stos dword ptr [rdi]
0000000140001420: 8B 8C 24 D0 00 00 mov ecx,dword ptr [rsp+0D0h]
0000000140001427: 48 8B 05 F2 EC 00 mov rax,qword ptr [__security_cookie]
000000014000142E: 48 33 C4 xor rax,rsp
0000000140001431: 48 89 84 24 B0 00 mov qword ptr [rsp+0B0h],rax
0000000140001439: 83 BC 24 D0 00 00 cmp dword ptr [rsp+0D0h],2
0000000140001441: 7D 1A jge 000000014000145D
0000000140001443: 48 8D 15 26 B7 00 lea rdx,[14000CB70h]
000000014000144A: 48 8B 0D 67 12 01 mov rcx,qword ptr [__imp_?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A]
0000000140001451: E8 B8 FC FF FF call @ILT+265(??$?6U?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@PEBD@Z)
0000000140001456: B8 FF FF FF FF mov eax,0FFFFFFFFh
000000014000145B: EB 42 jmp 000000014000149F
000000014000145D: B8 08 00 00 00 mov eax,8
0000000140001462: 48 6B C0 01 imul rax,rax,1
0000000140001466: 48 8B 8C 24 D8 00 mov rcx,qword ptr [rsp+0D8h]
000000014000146E: 48 8B 14 01 mov rdx,qword ptr [rcx+rax]
0000000140001472: 48 8D 4C 24 58 lea rcx,[rsp+58h]
0000000140001477: E8 DE 2F 00 00 call strcpy
000000014000147C: 48 8D 54 24 58 lea rdx,[rsp+58h]
0000000140001481: 48 8B 0D 30 12 01 mov rcx,qword ptr [__imp_?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A]
0000000140001488: E8 81 FC FF FF call @ILT+265(??$?6U?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@PEBD@Z)
000000014000148D: 48 8B 15 5C 11 01 mov rdx,qword ptr [__imp_?endl@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@1@AEAV21@@Z]
0000000140001494: 48 8B C8 mov rcx,rax
0000000140001497: FF 15 63 11 01 00 call qword ptr [__imp_??6?$basic_ostream@DU?$char_traits@D@std@@@std@@QEAAAEAV01@P6AAEAV01@AEAV01@@Z@Z]
000000014000149D: 33 C0 xor eax,eax
000000014000149F: 48 8B F8 mov rdi,rax
00000001400014A5: 48 8D 15 0C B7 00 lea rdx,[14000CBB8h]
00000001400014AC: E8 0F 30 00 00 call _RTC_CheckStackVars
00000001400014B1: 48 8B C7 mov rax,rdi
00000001400014B4: 48 8B 8C 24 B0 00 mov rcx,qword ptr [rsp+0B0h]
00000001400014BF: E8 5C 33 00 00 call __security_check_cookie
00000001400014C4: 48 81 C4 C0 00 00 add rsp,0C0h
00000001400014CB: 5F pop rdi
00000001400014CC: C3 ret
В таблице 2 приведена матрица смежности для данного участка кода.
-Matrix- #0
-Block- #0 Start=0x40001400 End=0x40001441
-Block- #1 Start=0x40001443 End=0x40001451
-Block- #2 Start=0x40001456 End=0x4000145B
-Block- #3 Start=0x4000145D End=0x40001477
-Block- #4 Start=0x4000147C End=0x40001488
-Block- #5 Start=0x4000148D End=0x40001497
-Block- #6 Start=0x4000149D End=0x400014AC
-Block- #7 Start=0x400014B1 End=0x400014BF
-Block- #8 Start=0x400014C4 End=0x400014CC
|
|
(0)
|
(1)
|
(2)
|
(3)
|
(4)
|
(5)
|
(6)
|
(7)
|
(8)
|
|
(0)
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(1)
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(2)
|
0
|
2
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(3)
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(4)
|
0
|
0
|
0
|
2
|
0
|
0
|
0
|
0
|
0
|
|
(5)
|
0
|
0
|
0
|
0
|
2
|
0
|
0
|
0
|
0
|
|
(6)
|
0
|
0
|
1
|
0
|
0
|
2
|
0
|
0
|
0
|
|
(7)
|
0
|
0
|
0
|
0
|
0
|
0
|
2
|
0
|
0
|
|
(8)
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
2
|
0
|
Таблица 2
В таблице 2 синим цветом обозначен блок кода, содержащий в себе вызов потенциально опасной функции strcpy. Жёлтым — блок кода, через который должен пройти поток управления для исполнения потенциально опасного кода. Отметим в данной таблице зеленым цветом ячейки, представляющие собой альтернативный путь исполнения программы. Таким образом, мы видим, что, несмотря на то, что переход в потенциально-опасный блок кода производится из нулевого блока кода, являющегося точкой входа анализируемого диапазона адресов, управление может пойти по другой ветке и потенциально опасный код не будет задействован.
Ещё несколько модифицируем изначальный код на языке программирования С/С++ (Листинг 5) и дизассемблированное представление его отрывка, содержащего в себе только часть для приведённого кода (Листинг 6). Как и ранее в листингах 5 и 6 приведен полный код для функций «main» и «evil_func», поскольку он является важным для сравнения с вновь построенной матрицей зависимостей.
Листинг 5
#include
#include
#define MAX_PARAMLENGTH 10
using namespace std;
void evil_func(char *evilC)
{
char arr0[MAX_PARAMLENGTH + 1];
char arr[MAX_PARAMLENGTH + 1];
char arr1[MAX_PARAMLENGTH + 1];
strcpy(arr, evilC);
}
int main(int argc, char *argv[])
{
if (argc < 2)
{
cout << "Start by: <programm_name.exe> <string_parameter>n";
return -1;
}
evil_func(argv[1]);
cout << "Evil_func has done his business!" << endl;
return 0;
}
Листинг 6
00000001400010FF: E9 0C 03 00 00 jmp 0000000140001410
0000000140001410: 48 89 4C 24 08 mov qword ptr [rsp+8],rcx
0000000140001415: 57 push rdi
0000000140001416: 48 81 EC C0 00 00 sub rsp,0C0h
000000014000141D: 48 8B FC mov rdi,rsp
0000000140001420: B9 30 00 00 00 mov ecx,30h
000000014000142A: F3 AB rep stos dword ptr [rdi]
000000014000142C: 48 8B 8C 24 D0 00 mov rcx,qword ptr [rsp+0D0h]
0000000140001434: 48 8B 05 E5 EC 00 mov rax,qword ptr [__security_cookie]
000000014000143B: 48 33 C4 xor rax,rsp
000000014000143E: 48 89 84 24 B0 00 mov qword ptr [rsp+0B0h],rax
0000000140001446: 48 8B 94 24 D0 00 mov rdx,qword ptr [rsp+0D0h]
000000014000144E: 48 8D 4C 24 58 lea rcx,[rsp+58h]
0000000140001453: E8 42 30 00 00 call strcpy
000000014000145B: 48 8D 15 3E B8 00 lea rdx,[14000CCA0h]
0000000140001462: E8 99 30 00 00 call _RTC_CheckStackVars
0000000140001467: 48 8B 8C 24 B0 00 mov rcx,qword ptr [rsp+0B0h]
0000000140001472: E8 E9 33 00 00 call __security_check_cookie
0000000140001477: 48 81 C4 C0 00 00 add rsp,0C0h
000000014000147E: 5F pop rdi
000000014000147F: C3 ret
0000000140001490: 48 89 54 24 10 mov qword ptr [rsp+10h],rdx
0000000140001495: 89 4C 24 08 mov dword ptr [rsp+8],ecx
0000000140001499: 57 push rdi
000000014000149A: 48 83 EC 20 sub rsp,20h
000000014000149E: 48 8B FC mov rdi,rsp
00000001400014A1: B9 08 00 00 00 mov ecx,8
00000001400014AB: F3 AB rep stos dword ptr [rdi]
00000001400014AD: 8B 4C 24 30 mov ecx,dword ptr [rsp+30h]
00000001400014B1: 83 7C 24 30 02 cmp dword ptr [rsp+30h],2
00000001400014B6: 7D 1A jge 00000001400014D2
00000001400014B8: 48 8D 15 B1 B6 00 lea rdx,[14000CB70h]
00000001400014BF: 48 8B 0D F2 11 01 mov rcx,qword ptr [__imp_?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A]
00000001400014C6: E8 48 FC FF FF call @ILT+270(??$?6U?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@PEBD@Z)
00000001400014CB: B8 FF FF FF FF mov eax,0FFFFFFFFh
00000001400014D0: EB 3C jmp 000000014000150E
00000001400014D2: B8 08 00 00 00 mov eax,8
00000001400014D7: 48 6B C0 01 imul rax,rax,1
00000001400014DB: 48 8B 4C 24 38 mov rcx,qword ptr [rsp+38h]
00000001400014E0: 48 8B 0C 01 mov rcx,qword ptr [rcx+rax]
00000001400014E4: E8 16 FC FF FF call 00000001400010FF
00000001400014E9: 48 8D 15 B8 B6 00 lea rdx,[14000CBA8h]
00000001400014F0: 48 8B 0D C1 11 01 mov rcx,qword ptr [__imp_?cout@std@@3V?$basic_ostream@DU?$char_traits@D@std@@@1@A]
00000001400014F7: E8 17 FC FF FF call @ILT+270(??$?6U?$char_traits@D@std@@@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@0@AEAV10@PEBD@Z)
00000001400014FC: 48 8B 15 ED 10 01 mov rdx,qword ptr [__imp_?endl@std@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@1@AEAV21@@Z]
0000000140001503: 48 8B C8 mov rcx,rax
0000000140001506: FF 15 F4 10 01 00 call qword ptr [__imp_??6?$basic_ostream@DU?$char_traits@D@std@@@std@@QEAAAEAV01@P6AAEAV01@AEAV01@@Z@Z]
000000014000150C: 33 C0 xor eax,eax
000000014000150E: 48 83 C4 20 add rsp,20h
0000000140001512: 5F pop rdi
0000000140001513: C3 ret
В таблице 3 приведена матрица смежности, полученная в ходе автоматизированного анализа дизассемблированного листинга 6.
-Matrix- #0
-Block- #0 Start=0x400010FF End=0x400010FF
-Block- #1 Start=0x40001410 End=0x40001453
-Block- #2 Start=0x4000145B End=0x40001462
-Block- #3 Start=0x40001467 End=0x40001472
-Block- #4 Start=0x40001477 End=0x4000147F
-Block- #5 Start=0x40001490 End=0x400014B6
-Block- #6 Start=0x400014B8 End=0x400014C6
-Block- #7 Start=0x400014CB End=0x400014D0
-Block- #8 Start=0x400014D2 End=0x400014E4
-Block- #9 Start=0x400014E9 End=0x400014F7
-Block- #10 Start=0x400014FC End=0x40001506
-Block- #11 Start=0x4000150C End=0x40001513
|
|
(0)
|
(1)
|
(2)
|
(3)
|
(4)
|
(5)
|
(6)
|
(7)
|
(8)
|
(9)
|
(10)
|
(11)
|
|
(0)
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
|
(1)
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(2)
|
0
|
2
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(3)
|
0
|
0
|
2
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(4)
|
0
|
0
|
0
|
2
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(5)
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(6)
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(7)
|
0
|
0
|
0
|
0
|
0
|
0
|
2
|
0
|
0
|
0
|
0
|
0
|
|
(8)
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(9)
|
4
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
(10)
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
2
|
0
|
0
|
|
(11)
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
2
|
0
|
Таблица 3
В таблице 3 мы видим числовой код «4», означающий вероятный возврат после перехода «call». Вызов происходит по адресу 0х00000001400014E4 и передает управление на инструкцию «jmp», расположенную по адресу 0х00000001400010FF, которая вызывает импортированную функцию strcpy. Как уже сообщалось раньше, мы полагаем, что вызовы завершаются в соответствии со стандартом и управление возвращается на следующую за вызовом инструкцию. Синим цветом выделена ячейка, соответствующая потенциально опасному блоку кода, жёлтым — переходы на пути в потенциально опасный блок кода. Оранжевым цветом отмечен номер блока кода, являющегося точкой входа для анализа. Потенциально уязвимым является блок кода №1, содержащий в себе функцию стандартной библиотеки языка программирования C/C++ «strcpy».
Поворотными точками будут являться адреса инструкций условного перехода, которые имеют непосредственное отношение для достижения заданного потенциально-опасного блока кода (инструкции условных переходов на пути к потенциально опасному блоку кода). На рассматриваемой матрице мы можем их определить, ориентируясь на ячейки, отмеченные жёлтым цветом. Столбцы, соответствующие данным ячейкам, представляют собой отдельные блоки кода с линейным ходом выполнения. Если столбец содержит значение «1» в двух ячейках (согласно инструкциям рассматриваемого набора процессоров команды условного перехода могут передавать управление только на 2 адреса: либо на адрес, указанный в качестве единственного аргумента, либо на следующий за данной инструкцией адрес), то мы имеем условную инструкцию. Из приведённой матрицы мы имеем путь: 5→8→0→{1}. Задействованный условный переход мы имеем в блоке кода №5.
Рассматриваемые примеры программ являются довольно небольшими, что дает возможность построить полный путь от точки входа информации в процесс до точки выхода. В реальных проектах такой путь может быть значительно длиннее. Как уже сообщалось ранее, анализ полного кода программы может занять длительное время. Таким образом, введя критерий глубины автоматизированного исследования кода, мы сокращаем продолжительность анализа. Однако данный подход снижает вероятность обнаружения уязвимости в тех случаях, когда точка входа информации в процесс и потенциально опасная функция расположены с большим количеством промежуточных операций перехода. В тех случаях, когда информация хранится по определенным адресам, а доступ осуществляется также с использованием соответствующего фиксированного адреса, не передаваемого через параметры на большую удаленность, данный метод можно несколько усовершенствовать для снижения вероятности потери точности. В качестве модификации метода может использоваться таблица доступных адресов памяти. При записи некоторой информации по определенному адресу, мы устанавливаем соответствующую отметку в таблице доступной памяти. В дальнейшем доступ по данным адресам будет определяться как установленная связь между точкой входа информации в процесс и потенциально опасным блоком кода. Однако дизассемблированные листинги современного программного обеспечения, содержащие в себе различные передачи указателей на область памяти в функцию, показали, что в большинстве случаев современные компиляторы не используют фиксированных адресов, предпочитая вести измерения относительно регистра RSP и т.п.
Восстанавливая пути передачи информации и рассматривая дизассемблированные листинги скомпилированных различными компиляторами с различными настройками, мы сталкиваемся с тем фактом, что передача информации между отдельными функциями может проводиться различными способами. Это несколько усложняет процесс автоматического анализа информационных потоков.
Заключение
Таким образом, мы получаем метод восстановления зависимостей между точками входа информации в процесс и потенциально опасными точками внутри исследуемой программы, основываясь лишь на дизассемблированном представлении соответствующего программного модуля. Кроме того, используя полученную информацию о путях информационных потоков на определенных диапазонах, мы можем оценить перспективность более подробного, в том числе динамического, тестирования исследуемого пути на наличие потенциальных уязвимости. Однако важно понимать, что данный подход является ресурсоемким в случае применения его к крупному исполняемому модулю целиком без использования критерия глубины исследования, ограничивающего автоматический анализ некоторыми заданными критериями.
References
1. Microsoft. Hardware Dev Center. x64 Architecture. [Elektronnyi resurs] URL: http://msdn.microsoft.com/en-us/library/windows/hardware/ff561499%28v=vs.85%29.aspx
2. Ablyazov R. Z. Programmirovanie na assemblere na platforme kh86_64. Ucheb. posobie / R. Z. Ablyazov. — Moskva: DMK Press, 2011. — 305 c. — ISBN: 978-5-94074-676-8.
3. Drozdov A. Yu., Kornev R. M., Bokhanko A. S. Indeksnyĭ analiz zavisimosteĭ po dannym // Informatsionnye tekhnologii i vychislitel'nye sistemy. — 2004. — № 3. URL: http://www.optimitech.com/docs/024.pdf
4. Evstigneev V. A., Arapbaev R. N., Osmonov R. A. Analiz zavisimostei: osnovnye testy na zavisimost' po dannym // Sibirskii zhurnal vychislitel'noi matematiki. — 2007. — T. 10. — № 3. — S. 247–265. — URL: http://www.mathnet.ru/links/42c6264864b854261516917954cde4b9/sjvm82.pdf
5. Arapbaev R. N., Osmonov R. A. Analiz zavisimosteĭ po dannym dlya mnogomernykh massivov na baze modifitsirovannogo λ-testa // Problemy intellektualizatsii i kachestva sistem informatiki. — Novosibirsk: ISI SO RAN, 2006. — S. 7–23. — URL: http://www.iis.nsk.su/files/articles/sbor_kas_13_arapbaev_osmonov.pdf
6. Hex-rays. IDA: About. [Elektronnyi resurs] URL: https://www.hex-rays.com/products/ida/
7. Velizhanin A. S., Revnivykh A. V. Evristicheskii metod poiska uyazvimostei v PO bez ispol'zovaniya iskhodnogo koda // XIV Rossiiskaya konferentsiya s mezhdunarodnym uchastiem «Raspredelennye informatsionnye i vychislitel'nye resursy» (DICR-2012). — ISBN 978-5-905569-05-0. — URL: https://docplayer.ru/87603686-Evristicheskiy-metod-poiska-uyazvimostey-v-po-bez-ispolzovaniya-ishodnogo-koda.html
8. Mukhanova A. A., Revnivykh A. V., Fedotov A. M. Klassifikatsiya ugroz i uyazvimostei informatsionnoi bezopasnosti v korporativnykh sistemakh // Vestnik NGU. Ser.: Informatsionnye tekhnologii. — 2013. — T. 11. — № 2. –—S. 55–72. — ISSN 1818-7900.
9. Revnivykh A. V., Fedotov A. M. Monitoring informatsionnoi infrastruktury organizatsii // Vestnik NGU. Ser.: Informatsionnye tekhnologii. — 2013. — T. 11. — № 4. — S. 84–91. — URL: https://nsu.ru/xmlui/bitstream/handle/nsu/1295/2013_V11_N4_8.pdf.
10. Voropaev D. P., Zaugolkov I. A. Issledovanie programmnykh uyazvimostei v komp'yuternykh sistemakh i analiz primenyaemogo programmnogo obespecheniya dlya provedeniya atak na vychislitel'nuyu sistemu // Vestnik Tambovskogo universiteta. Seriya: Estestvennye i tekhnicheskie nauki. — 2014. — T. 19. — № 2. — S. 637–638. — ISSN 1810-0198. —URL: https://cyberleninka.ru/article/v/issledovanie-programmnyh-uyazvimostey-v-kompyuternyh-sistemah-i-analiz-primenyaemogo-programmnogo-obespecheniya-dlya-provedeniya-atak
11. Nurmukhametov A. R., Kurmangaleev Sh. F., Kaushan V. V., Gaisaryan S. S. Primenenie kompilyatornykh preobrazovanii dlya protivodeistviya ekspluatatsii uyazvimostei programmnogo obespecheniya // Trudy instituta sistemnogo programmirovaniya RAN. — 2014. — T. 26. — № 3. — S. 113–124. — ISSN 2079-8156.
12. Fedotov A. N. Metod otsenki ekspluatiruemosti programmnykh defektov // Trudy instituta sistemnogo programmirovaniya RAN. — 2016. — T. 28. — № 4. — S. 137–148. — DOI: 10.15514/ISPRAS-2016-28(4)-8.
13. Fedotov A. N., Kaushan V. V., Gaisaryan S. S., Kurmangaleev Sh. F. Postroenie predikatov bezopasnosti dlya nekotorykh tipov programmnykh defektov // Trudy instituta sistemnogo programmirovaniya RAN. — 2017. — T. 29. — № 6. — S. 151–162. — DOI: 10.15514/ISPRAS-2017-29(6)-8.
14. Shudrak M. O., Kheirkhabarov T. S. Avtomatizirovannyi poisk uyazvimostei v binarnom kode // Reshetnevskie chteniya. Sibirskii gosudarstvennyi aerokosmicheskii universitet im. akad. M. F. Reshetneva. — 2012. —T. 16. — № 2. — S. 691–692.
15. Vakhrushev I. A., Kaushan V. V., Padaryan V. A., Fedotov A. N. Metod poiska uyazvimosti formatnoi stroki // Trudy instituta sistemnogo programmirovaniya RAN. — 2015 — T. 27. — № 4. — S. 23–34. — ISSN 2079-8156. — DOI: 10.15514/ISPRAS-2015-27(4)-2.
16. Padaryan V. A., Kaushan V. V., Fedotov A. N. Avtomatizirovannyi metod postroeniya eksploitov dlya uyazvimosti perepolneniya bufera na steke // Trudy instituta sistemnogo programmirovaniya RAN. — 2014. — T. 26. — № 6. — S. 127–144. — ISSN 2079-8156.
17. Nurmukhametov A. R., Zhabotinskii E. A., Kurmangaleev Sh. F., Gaisaryan S. S., Vishnyakov A. V. Melkogranulyarnaya randomizatsiya adresnogo prostranstva programmy pri zapuske // Trudy instituta sistemnogo programmirovaniya RAN. — 2014. — T. 29. — № 6. — S. 163–182. — ISSN 2079-8156.
18. Fedotov A. N., Padaryan V. A., Kaushan V. V., Kurmangaleev Sh. F., Vishnyakov A. V., Nurmukhametov A. R. Otsenka kritichnosti programmnykh defektov v usloviyakh raboty sovremennykh zashchitnykh mekhanizmov // Trudy instituta sistemnogo programmirovaniya RAN. — 2016. — T. 28. — № 5. — S. 73–92. — DOI: 10.15514/ISPRAS-2016-28(5)-4.
19. Nadezhdin E. N., Shchiptsova E. I., Shershakova T. L. Analiz uyazvimostei programmnogo obespecheniya pri proektirovanii mekhanizma integrirovannoi zashchity korporativnoi informatsionnoi sistemy // Sovremennye naukoemkie tekhnologii. — 2017. — № 10. — S. 32–38. — ISSN 1812-7320. — URL: http://www.top-technologies.ru/ru/article/view?id=36824
20. Mironov S. V., Kulikov G. V. Tekhnologii kontrolya bezopasnosti avtomatizirovannykh sistem na osnove strukturnogo i povedencheskogo testirovaniya programmnogo obespecheniya // Kibernetika i programmirovanie. — 2015. — № 5. — S.158–172. — ISSN 2306-4196. — DOI: 10.7256/2306-4196.2017.1.20351
21. Azymshin I. M., Chukanov V. O. Analiz bezopasnosti programmnogo obespecheniya // Bezopasnost' informatsionnykh tekhnologii. — 2014. —№ 1. — S. 45–47. — ISSN 2074-7136.
22. Sosnin Yu. V., Kulikov G. V., Nepomnyashchikh A. V. Kompleks matematicheskikh modelei optimizatsii konfiguratsii sredstv zashchity informatsii ot nesanktsionirovannogo dostupa // Programmnye sistemy i vychislitel'nye metody. — 2015. — № 1. — S. 32–44. — ISSN 2305-6061. — DOI: 10.7256/2305-6061.2015.1.14124
23. Nepomnyashchikh A. V., Kulikov G. V., Sosnin Yu. V., Nashchekin P. A. Metody otsenivaniya zashchishchennosti informatsii v avtomatizirovannykh sistemakh ot nesanktsionirovannogo dostupa // Voprosy zashchity informatsii. — 2014. — № 1 (104). — S. 3–12. — ISSN 2073-2600.
24. Kozachok A. V., Kochetkov E. V. Obosnovanie vozmozhnosti primeneniya verifikatsii programm dlya obnaruzheniya vredonosnogo koda. Voprosy kiberbezopasnosti. — 2016. — Byp. 3(16). — S. 25–32. — ISSN 2311-3456. — URL: https://cyberleninka.ru/article/v/obosnovanie-vozmozhnosti-primeneniya-verifikatsii-programm-dlya-obnaruzheniya-vredonosnogo-koda
| 
 Eng
Eng








