|
Litera
Reference:
Lemaev V.I., Lukashevich N.V.
Automatic classification of emotions in speech: methods and data
// Litera.
2024. ą 4.
P. 159-173.
DOI: 10.25136/2409-8698.2024.4.70472 EDN: WOBSMN URL: https://en.nbpublish.com/library_read_article.php?id=70472
Automatic classification of emotions in speech: methods and data
Lemaev Vladislav Igorevich
Postgraduate student, Department of Theoretical and Applied Linguistics, Lomonosov Moscow State University
119991, Russia, Moscow, Leninskie Gory, 1c51

|
vladzhkv98@mail.ru
|
|
 |
|
Lukashevich Natal'ya Valentinovna
Doctor of Technical Science
Professor, Department of Theoretical and Applied Linguistics, Lomonosov Moscow State University
119991, Russia, Moscow, Leninskie Gory, 1s51, room 953
|
|
louk_nat@mai.ru
|
|
|
|
DOI: 10.25136/2409-8698.2024.4.70472
EDN: WOBSMN
Received:
14-04-2024
Published:
21-04-2024
Abstract:
The subject of this study is the data and methods used in the task of automatic recognition of emotions in spoken speech. This task has gained great popularity recently, primarily due to the emergence of large datasets of labeled data and the development of machine learning models. The classification of speech utterances is usually based on 6 archetypal emotions: anger, fear, surprise, joy, disgust and sadness. Most modern classification methods are based on machine learning and transformer models using a self-learning approach, in particular, models such as Wav2vec 2.0, HuBERT and WavLM, which are considered in this paper. English and Russian datasets of emotional speech, in particular, the datasets Dusha and RESD, are analyzed as data. As a method, an experiment was conducted in the form of comparing the results of Wav2vec 2.0, HuBERT and WavLM models applied to the relatively recently collected Russian datasets of emotional speech Dusha and RESD. The main purpose of the work is to analyze the availability and applicability of available data and approaches to recognizing emotions in speech for the Russian language, for which relatively little research has been conducted up to this point. The best result was demonstrated by the WavLM model on the Dusha dataset - 0.8782 dataset according to the Accuracy metric. The WavLM model also received the best result on the RESD dataset, while preliminary training was conducted for it on the Dusha - 0.81 dataset using the Accuracy metric. High classification results, primarily due to the quality and size of the collected Dusha dataset, indicate the prospects for further development of this area for the Russian language.
Keywords:
natural language processing, emotion recognition, speech recognition, machine learning, transformers, Wav2vec, HuBERT, WavLM, Dusha, RESD
This article is automatically translated.
You can find original text of the article here.
Introduction The purpose of creating emotion recognition systems is to determine the internal state of the speaker by analyzing his speech. Such systems are widely used both in the areas of human-computer interaction and in various security systems (for example, when determining the emotional state of a car driver). The task of automatic emotion recognition contains many difficulties that may not be obvious to a person unfamiliar with the field. Thus, speech and expression of emotions vary depending on many parameters, be it different age groups of speakers, different languages, different cultural backgrounds. At the same time, it is not very clear which of the acoustic signs in this case will be most important for the classification of emotions. Moreover, one speech utterance may contain several expressed emotions at once, each of which refers to a separate speech fragment. The creation of an automatic emotion recognition system is divided into two main stages – the collection of training data and the creation of an emotion classification algorithm. The first stage is currently relatively solved for the English language, for which there are many works on this topic and a significant amount of training data is freely available, but for other languages there is still a lack of labeled data. Approaches to solving the second stage, however, do not stop actively developing to this day. The most promising at the moment are the recently appeared models based on the transformer architecture, such as Wav2Vec [1], which allow you to automatically analyze the available data and, based on them, independently classify new, previously unknown statements. The article describes the problem of automatic emotion recognition and approaches to its solution. The purpose of the article is to compare the results of frequently used methods based on transformers based on the material of the Russian language. Section 1 describes the emotion inventories on the basis of which the classification is made. Section 2 is devoted to the collection and processing of data, as well as the currently available corpus of emotional speech. Section 3 provides classification methods that are actively used by researchers in their work, including in this article. Finally, section 4 describes testing and comparing the results of emotion classification obtained by different models. 1. Making an inventory of emotions One of the primary problems of the field is the definition of an inventory of emotions, on the basis of which classification should be carried out. The very concept of emotion still does not have a consistent theoretical definition, and those emotions that are expressed in speech have high variability and overlap. Typical sets of emotions used in theoretical and practical fields of psychology include about 300 different emotions and their variations. However, this number is extremely difficult to implement in an automatic classification task. Therefore, researchers usually use a set of 6 basic emotions, into which it is often customary to decompose all other emotions — anger, fear, surprise, joy, disgust and sadness [2]. These emotions are universal for most languages and are called archetypal. Most datasets use this set of emotions, often modifying it in one way or another [3, 4]. In addition to classification based on a set of emotions, researchers also apply a two-dimensional space-based classification approach. The first axis of such a space is the concept of "valence", which describes the emotion expressed in the space of "positivity-negativity". The second axis is the concept of "arousal", which describes the degree of manifestation of the emotion being expressed. Such a two-dimensional space is highly correlated with the archetypal emotions mentioned above. Thus, the excitation of the sympathetic nervous system occurs when expressing emotions of anger, fear and joy and leads to an increased heart rate, muscle tension, increased blood pressure and dry mouth, fast and energetic speech. On the contrary, the expression of the emotion of sadness leads to arousal of the parasympathetic system and manifests itself in a lowered heart rate and blood pressure, which in turn is reflected in slow and quiet, often low-tonal speech. These speech characteristics are used to assess the degree of manifestation of emotion along the "arousal" axis. However, although the degree of energy activation helps to distinguish between emotions of sadness and joy, it does not make it possible to distinguish between emotions of joy and anger. The "valence" space is used for this purpose, but, unfortunately, researchers do not have a clear understanding of which of the acoustic characteristics it correlates with. Recent studies show that the use of transformers makes it possible to improve the quality of prediction on the "jackiness" scale due to implicit linguistic information [5]. 2. Data for recognizing emotions in speech One of the most important tasks in designing such systems is the collection of training data, a large amount of which is necessary for machine learning-based methods that are actively used at the moment. Databases of emotional statements can be categorized in terms of naturalness, emotions, speakers, language, etc. Naturalness is one of the most important parameters that should be taken into account when collecting statements and creating a database. There are 3 degrees of naturalness of speech: natural, semi-natural and artificial. In databases with natural speech [6], material is usually collected from real everyday situations in order to record real emotions. However, such data is rarely used in real research due to the legal and moral limitations that may arise with this approach. Therefore, for research, speech material is usually specially recorded separately with the involvement of volunteers. Databases with semi-natural speech use 2 approaches: script-based (for example, [4]) and acting-based [7]. In the first approach, the speaker must first enter the desired emotional state (joy, anger, etc.) – this can be done through experiencing various memories, computer games, or dialogue with a computer (the latter method is called the Wizard of Oz). Then the speaker is given a pre-written text to read, which corresponds in content to his emotional state. In the second approach, language data is extracted from films and radio productions.
Finally, databases with artificial speech use pre-written texts (usually in a neutral style), which are given to professional actors to read with a given emotion. The main problem with this approach is often the affectation of various emotions. To solve it, recordings are sometimes carried out with the involvement of people who do not have professional acting skills. For example, in the database of Danish emotional speech [8], statements by semi-professional actors were recorded so that emotions were more close to real speech situations. In addition to acting experience, it is also important to take into account other characteristics of speakers, namely age, gender, and native language. Men and women, as well as the elderly and teenagers, express emotions differently in their speech, therefore, for most datasets, which aim at universality and applicability for various studies, it is important to balance speakers by gender and age groups so that the classifying algorithm can recognize them with equal confidence. The native language of the speakers usually corresponds to the language for which the dataset is created. However, even within the same language, there are many dialects and local dialects, but they are usually not included in datasets, except for directed research. In addition, multilingual datasets are also being created in order to study the expression of emotions in different languages and create a universal model [9]. When creating a corpus, it is also important to take into account the duration of statements and their number. So, in general, statements should not be too long or too short. The average length of an utterance should ideally be about 7 seconds (ranging from 3 to 11 seconds [10]). If the length is too long, emotions can alternate or change — especially when extracting statements from movies or TV shows. If the length of the utterance is too small, there will be too few signs that are necessary to classify the emotions expressed. However, although such data helps to achieve good results in recognizing emotions in a controlled environment, they do not reflect the real picture of their expression well. To increase validity, the dataset can be made up of unbalanced statements in length, but for good results, the volume requirements for it will be higher. It is also important to take into account the distribution of statements by class. To properly assess the quality of emotion recognition, the number of statements for each of the classified emotions should be approximately the same. However, in reality, the frequency of occurrence of each emotion depends on the conditions in which communication takes place. So, when extracting data from TV shows, especially those dealing with social or political topics, the number of statements with negative emotions will prevail [11]. When recording a dialogue in controlled conditions between little–known participants – who, for example, are trying to jointly solve a task given to them - the statements will be predominantly positive or neutral in emotional color. Finally, it is important to take into account the lexical diversity of statements, that is, the number of unique words in them. This is especially necessary when reading sentences with predetermined emotions. Often in such cases, the same lexical sentences are voiced several times with different emotions, so the lexical diversity may be low, which reduces the further effectiveness of the classifier. It is important to create several sets of sentences that are as lexically diverse as possible. For English, the most popular datasets are IEMOCAP and RAVDESS. For the Russian language, among the currently publicly available datasets, it is necessary, first of all, to highlight the Dusha and RESD datasets. Let's take a closer look at the available datasets. Table 1 contains the characteristics of the most well-known datasets. IEMOCAP (Interactive Emotional Dyadic Motion Capture Database) [4] is a multimodal dataset created to study communication between people and consisting of more than 12 hours of audio and video recordings of conversations between actors. The dataset includes 5 dialogues between actors (2 actors in each conversation), 5 men and 5 women participated in the recordings. The actors were asked to play pre-composed lines, as well as improvise a dialogue in the proposed scenario, in order to evoke certain emotions. Each session was recorded using a special motion capture system, which made it possible to obtain not only audio recordings, but also information about the movements of the face, head and hands. There are 5 classes of emotions in total: Joy, Anger, Sadness, Disgust and a Neutral state. This dataset is currently the most popular in automatic emotion recognition tasks. RAVDESS [12] is one of the most popular datasets used in speech and singing emotion recognition tasks. The dataset has a large volume (7,356 statements) and contains audio and video recordings of professional actors living in North America. The participants read and sang the sentences assigned to them. In total, the dataset contains recordings of 24 actors (12 men and 12 women). The emotions of Calmness, Joy, Sadness, Anger, Fear and Disgust were highlighted for the speech recordings. For recordings with singing – Calmness, Joy, Sadness, Anger and Fear. A distinctive feature of this dataset is that each emotion has two degrees of intensity – weak and strong. RAVDESS is widely used in research and development of emotion recognition systems. It provides a good dataset for training and testing machine learning models that analyze emotions based on audio and video data. The Dusha dataset [3] was created by the company SberDevices and is currently the largest dataset in Russian designed to solve problems of recognizing emotions in spoken speech. The dataset is divided into 2 parts: for the first part, called Crowd, the authors generated texts based on the communication of real people with a virtual assistant, which were then voiced using crowdsourcing (the speakers were given the text and the emotion with which this text was to be spoken, and then the received audio recordings were additionally checked by the second group); the second part was called The Podcast title contains short (up to 5 words) excerpts from Russian-language podcasts, which were then classified by emotion. There are 5 classes of emotions in total: Anger, Sadness, Positive, Neutral and More. The resulting dataset contains about 300 thousand audio recordings lasting about 350 hours and their written transcripts.
RESD (Russian Emotional Speech Dialogues) [13] is a Russian–language dataset presented in the Aniemore open library designed to process and recognize the emotional coloring of spoken and written speech. Dialogues with preset emotions were composed for the recording, which were then voiced by the actors. In total, the dataset contains about 4 hours of recorded speech (about 1400 audio recordings) and a corresponding written transcript of each audio recording. The classification is made into 7 emotions: Neutral, Anger, Enthusiasm, Fear, Sadness, Joy and Disgust. | The name of the dataset | Volume | Number of speakers | The method of creation | Data types | Languages | Classification into emotions (including neutral state) | | IEMOCAP | 151 recordings (more than 12 hours) | 10 | Reading lines and improvisation (dialogue) | Audio and video | English | Anger, Joy, Sadness, Disgust | | RAVDESS | 7,356 statements | 24 |
Reading the lines | Audio and video | English (North American accent) | Anger, Joy, Sadness, Disgust, Fear, Surprise, Calmness | | Dusha | 300,000 records (350 hours) | More than 2000 | Reading replicas / extracting from podcasts | Audio | Russian | Anger, Sadness, Positive, Other | | RESD | 1400 entries (4 hours) | About 50 | Reading the dialogues | Audio | Russian | Anger, Enthusiasm, Fear, Sadness, Joy, Disgust | Table 1. Characteristics of datasets
3. Classification methods Early approaches to the task of automatic emotion recognition consisted mainly of manual extraction of features, which were then submitted to classical classification algorithms such as SVM [14] and Random Forest [15]. Spectral features were the most popular. One of them were MFCC features [16], which are also used in modern models, for example, in HuBERT (see below). MFCC features simulate the characteristics of the speaker's vocal tract, thereby allowing the analysis of the sound uttered at a particular time. The next important stage was the development of neural networks in the field of natural language processing, which first demonstrated good results in text classification tasks, and then attracted attention in the task of automatic emotion recognition [17]. The approach using the LSTM model [18] was the most popular at that time. In recent years, the Self-Supervised Learning (SSL) approach has come to the fore. It allows algorithms to independently find patterns in the source data and thereby achieve better results. This approach opens up the possibility of using huge amounts of data for training, up to all the data available on the Internet. This became possible primarily due to the advent of the transformer architecture [19], which, unlike previous neural network models, allowed parallelization of data processing during training. Most of the models created on the basis of self-learning are in the public domain and for good results, they require only a little additional training on data from the relevant field before application. One of the most well-known self-learning models based on the transformer architecture is BERT [20], which was created by Google Corporation researchers for the purpose of processing written language and is actively used in forming responses to queries in the search engine of the same name. However, BERT is not as well suited for processing spoken speech as it is for processing written speech. First, BERT requires separate tokens to enter, that is, words or parts of them. In this case, it is necessary to use a tokenizer for speech, and this is an additional task, during which there will be a lot of noise in the received data. Secondly, BERT himself is trained on a large corpus of text data, and their style is poorly suited for spoken speech. Special models have been proposed for the tasks of processing spoken language. Among them, the most popular at the moment are Wav2vec 2.0 [21], HuBERT [22] and WavLM [23]. All models work directly with raw source audio recordings, dividing them into “frames” – short segments, usually lasting 20 ms. Wav2vec 2.0 randomly masks some frames of the audio recording coming to the input and learns to predict these masked frames, thereby obtaining a high-quality representation of the audio data without additional markup. Wav2vec 2.0 has the architecture shown in Figure 1. 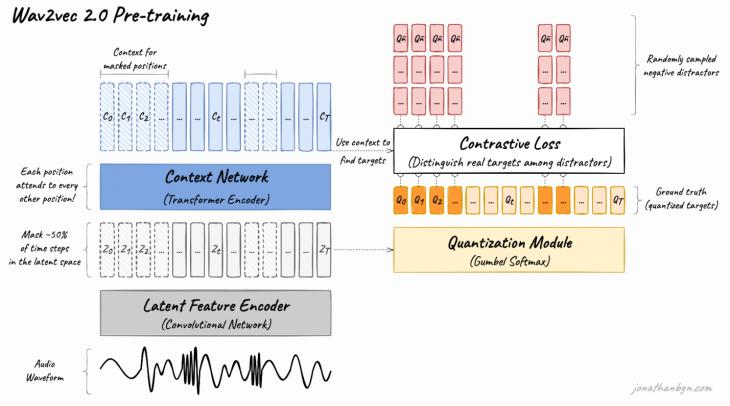
Figure 1. Wav2vec 2.0 architecture First, the original audio recording is transmitted through the source data encoding module, which consists of 7 convolutional layers (Fig. 2) and turns the audio recording into a sequence of vectors for every 20 ms of recording. Each convolutional layer has a dimension of 512 (the number of filters), and the filter dimension and the width of the convolution step gradually decrease with subsequent layers. The vectors obtained at this stage undergo a quantization stage in order to translate continuous values into a certain set of finite ones. To do this, Wav2vec 2.0 uses two “codebooks” of 320 “codewords" each. The available vectors are multiplied by the quantization matrix Wq, after which the Gumbel softmax function [24] is applied to the result, which outputs the most suitable code words for each source vector (one from each group). These codewords are concatenated and the final representation is obtained by linear transformation. The following steps are used to pre-train the model. Vectors extracted from the audio recording (obtained before quantization) are masked with a 50% probability. To do this, 0.065% plus nine subsequent vectors are randomly selected from the ordered vectors, taking into account the overlap. These vectors are replaced with the same masking vector. Next, all available vectors pass through the projective layer, which increases their dimension (768 for the BASE model and 1024 for the LARGE model). The next stage is the basis of the model and consists of a transformer with a sequence of 12 or 24 encoders for BASE and LARGE models, respectively. Previously, each vector also goes through a layer of positional coding. Unlike the original transformer model, in which positional encoding is implemented by concatenating pre-generated positional embeddings and input vectors, Wav2vec 2.0 uses a group convolution layer [25]. Finally, the vectors obtained after passing through the transformer pass through a projective layer, which reduces their dimension to the dimension of the vectors obtained at the quantization stage, after which it compares them and calculates the loss function. The loss function is calculated as the sum of the contrastive (contrastive loss) and the distinctive (diversity loss) errors. To calculate the contrastive error, the model must, based on the obtained vector, predict the true quantized vector Qp from K+1 vectors, where K=100 distracting vectors extracted from other positions of the same entry. The distinguishing error is used for regularization so that all possible code words from groups 320*320 are used with the same probability. 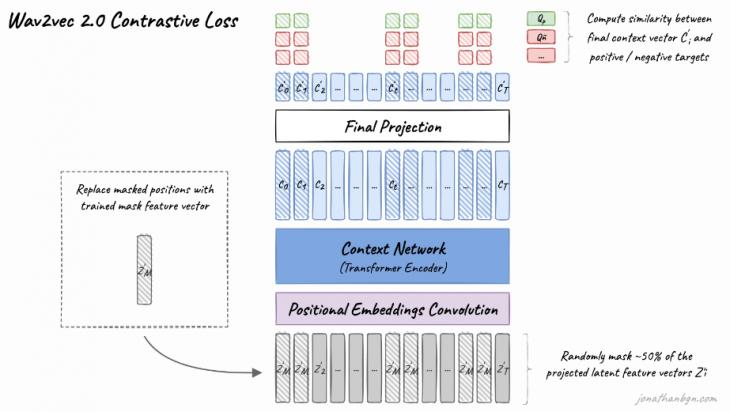
Fig. 2. Wav2vec 2.0 pre-training process Finally, the resulting model is ready for further training on the corresponding task. HuBERT uses a similar approach, but the training solves the classification problem, during which the model predicts one of the finite list of classes for each frame. The algorithm consists of two main stages: the class creation stage and the prediction stage. At the stage of creating classes, HuBERT extracts MFCC features directly from the audio recording for every 20 ms of recording, after which the resulting vectors are clustered using the k-means method. After that, each vector is assigned a corresponding class, and an embedding is created for each class, which is then used in calculating the loss function.
According to the architecture, the prediction stage of the HuBERT model completely repeats the Wav2vec 2.0 model, except for two things: firstly, the classes of masked vectors that have not been quantized are predicted, as already mentioned, and secondly, the cross-entropy function is used in HuBERT as a loss function. The initial features, just like in Wav2vec 2.0, are extracted using a convolutional neural network. After the first iteration, HuBERT updates its set of prediction classes. To do this, the second iteration uses vectors obtained on the 6th layer of encoders, which are similarly clustered by the k-means method (Fig. 3). The BASE model has only 2 iterations, the LARGE and X-LARGE models have already 3 iterations. In the third iteration, the vectors obtained on the 9th layer of the encoders of the second iteration are already used. The X-LARGE model differs from the LARGE model by doubling the number of encoder layers. 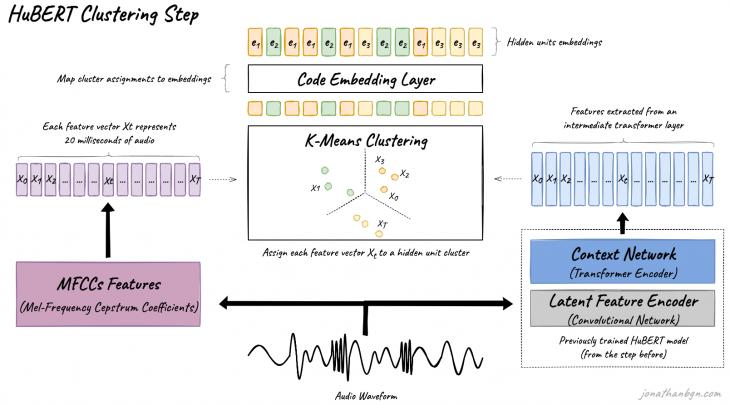
Fig. 3. Clustering stage of the HuBERT model WavLM uses the same pseudo-class prediction approach for frames as HuBERT, but also adds the task of speaker separation and noise reduction. To do this, noise or a fragment of an audio recording is superimposed on the masked vectors, and the model needs to predict the class of the original vector. Thus, the model learns not only the task of speech recognition, but also, for example, its division into different speakers. The WavLM architecture also repeats HuBERT, but it has been slightly modified: if HuBERT uses conventional relative positional encoding, then WavLM uses relative positional encoding with gates. The idea of gates is borrowed from the recurrent neural network architecture of GRU [26] and allows you to take into account the content of speech fragments when encoding the distance between them. WavLM currently shows the highest quality among all Self-Supervised Learning models in the task of recognizing emotions on the IEMOCAP dataset – 70.62% accuracy (based on the SUPERB benchmark [27]). 4. Testing Russian Russian Dasha and RESD datasets were used to test the effectiveness of the described methods for automatic recognition of emotions in the Russian language. wav2vec 2.0, HuBERT and WavLM models were used for testing. Specifically, freely available models on the Hugging Face platform, pre-trained on the Dusha dataset, and models from the Animore library, pre-trained on the RESD dataset, were used. During testing, all models were retrained on this very dataset with the parameters: 2 epochs, the size of the batch is 32 (2 * 16 steps of gradient accumulation), AdamW as an optimizer. The results are presented in Tables 2 and 3 in the format “model name — name of the initial dataset". At the same time, the models from the Aniemore library have the results indicated by the authors of the original model. Accuracy (also called Weighted Accuracy (WA)) was used as the main metric, which is considered standard in the task of automatic emotion recognition and is calculated as the ratio of correctly predicted classes to incorrectly predicted ones. | Model | Anger | Positive | Sadness | Neutral | Other | Accuracy | | HuBERT_Base-Dusha | 0.83 | 0.78 |
0.79 | 0.94 | 0.71 | 0.866 | | HuBERT_Large-Dusha | 0.87 | 0.81 | 0.80 | 0.93 | 0.7 | 0.8745 | | WavLM_Base-Dusha | 0.87 | 0.77 | 0.83 | 0.94 | 0.82 | 0.872 | | WavLM_Large-Dusha |
0.86 | 0.81 | 0.84 | 0.93 | 0.75 | 0.8782 | | Wav2vec2-RESD | 0.66 | 0.59 | 0.59 | 0.9 | 0.59 | 0.8063 | | HuBERT-RESD | 0.68 | 0.59 | 0.49 | 0.91 |
0.64 | 0.8134 | | WavLM-RESD | 0.65 | 0.53 | 0.54 | 0.92 | 0.63 | 0.8015 | Table 2. Training and testing of models on the Dusha dataset | Model | Anger | Joy | Enthusiasm | Sadness | Disgust | Fear | Neutral | Accuracy | | HuBERT_Base-Dusha |
0.34 | 0 | 0.03 | 0.03 | 0.22 | 0.02 | 0.39 | 0.1464 | | HuBERT_Large-Dusha | 0.14 | 0.48 | 0.1 | 0 | 0.03 | 0.33 | 0.11 | 0.1821 | | WavLM_Base-Dusha |
0.73 | 0.11 | 0 | 0.14 | 0.03 | 0.04 | 0 | 0.1571 | | WavLM_Large-Dusha | 0.11 | 0 | 0 | 0.06 | 0.32 | 0 | 0.42 | 0.125 | | Wav2vec2_Large-RESD |
0.91 | 0.59 | 0.7 | 0.63 | 0.76 | 0.67 | 0.79 | 0.72 | | HuBERT_Large-RESD | 0.84 | 0.7 | 0.8 | 0.78 | 0.73 | 0.67 | 0.74 | 0.75 | | WavLM_Large-RESD |
0.89 | 0.84 | 0.86 | 0.84 | 0.84 | 0.69 | 0.76 | 0.81 | Table 3. Training and testing of models on the RESD dataset The training was conducted only on audio data, without the use of text. At the same time, there are no wav2vec 2.0 models among the models pre-trained on the Dusha dataset. The WavLM_Large model, pre-trained and tested on the Dusha dataset, shows the best result. In second place, with a slight lag, HuBERT is Large_Dusha. The information from the SUPERB benchmark is confirmed, including the fact that the WavLM_Base model performs worse than HuBERT_Large, so the number of trained parameters still plays an important role even when the architecture is modified. Transferring models from one dataset to another shows worse results than the initial training itself. At the same time, the results on the RESD dataset turned out to be extremely low, which can be explained by its small size. As for emotions, it is easiest for models in the Dusha dataset to identify neutral emotion and anger. Emotions from the “Other” category are the worst defined. Perhaps, with a more detailed classification of this category, the quality of the results could also be improved. In the RESD dataset, the WavLM model determines all emotions with relatively equal accuracy, except fear and neutral, which stand out worse here. Anger is still better defined than other emotions. 5. Conclusion This article discusses the main approaches in the field of automatic recognition of emotions in speech that are currently in use. The most popular approach in recent years has been the approach based on self-learning models of transformers focused on spoken language processing, such as Wav2vec 2.0, HuBERT and WavLM. The training data collection stage is still critical for good model performance. Russian Russian datasets created for the tasks of analyzing emotional colloquial speech, such as Dusha and RESD, have relatively recently appeared, helped to reduce costs at this stage and provided new opportunities for the development of this field in relation to the Russian language, in particular for independent researchers. Transformer models show particularly good results on the Dusha dataset, primarily due to the large amount of data collected. As further research, it seems promising to explore the possibility of further complicating speech analysis models, for example, by taking into account the allocation of different levels in the speech signal (phonemes, syllables, words) [28], as well as using a multimodal approach with the addition of written data duplicating speech.
References
1. Schneider, S., Alexei Baevski, Ronan Collobert, & Auli, M. (2019). wav2vec: Unsupervised Pre-Training for Speech Recognition. ArXiv (Cornell University). doi:10.48550/arXiv.1904.05862
2. Cowie, R., Douglas-Cowie, E., Tsapatsoulis, N., Votsis, G., Kollias, S., Fellenz, W., & Taylor, J. G. (2001). Emotion recognition in human-computer interaction. IEEE Signal Processing Magazine, 18(1), 32–80. doi:10.1109/79.911197
3. Kondratenko, V., Sokolov, A., Karpov, N., Kutuzov, O., Savushkin, N., & Minkin, F. (2022). Large Raw Emotional Dataset with Aggregation Mechanism. ArXiv (Cornell University). doi:10.48550/arxiv.2212.12266
4. Busso, C., Bulut, M., Lee, C.-C., Kazemzadeh, A., Mower, E., Kim, S., Chang, J. N., Lee, S., & Narayanan, S. S. (2008). IEMOCAP: interactive emotional dyadic motion capture database. Language Resources and Evaluation, 42(4), 335–359. doi:10.1007/s10579-008-9076-6
5. Wagner, J., Triantafyllopoulos, A., Wierstorf, H., Schmitt, M., Burkhardt, F., Eyben, F., & Schuller, B. W. (2023). Dawn of the Transformer Era in Speech Emotion Recognition: Closing the Valence Gap. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1–13. doi:10.1109/tpami.2023.3263585
6. Kossaifi, J., Walecki, R., Panagakis, Y., Shen, J., Schmitt, M., Ringeval, F., Han, J., Pandit, V., Toisoul, A., Schuller, B., Star, K., Hajiyev, E., & Pantic, M. (2021). SEWA DB: A Rich Database for Audio-Visual Emotion and Sentiment Research in the Wild. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(3), 1022–1040. doi:10.1109/tpami.2019.2944808
7. Mohamad Nezami, O., Jamshid Lou, P., & Karami, M. (2018). ShEMO: a large-scale validated database for Persian speech emotion detection. Language Resources and Evaluation, 53(1), 1–16. doi:10.1007/s10579-018-9427-x
8. Inger Samsø Engberg, Anya Varnich Hansen, Ove Kjeld Andersen, & Dalsgaard, P. (1997). Design, recording and verification of a danish emotional speech database. EUROSPEECH, 4, 1695-1698. doi:10.21437/eurospeech.1997-482
9. Hozjan, V., & Kačič, Z. (2003). Context-Independent Multilingual Emotion Recognition from Speech Signals. International Journal of Speech Technology, 6, 311–320. doi:10.1023/A:1023426522496
10. Lotfian, R., & Busso, C. (2019). Building Naturalistic Emotionally Balanced Speech Corpus by Retrieving Emotional Speech from Existing Podcast Recordings. IEEE Transactions on Affective Computing, 10(4), 471–483. doi:10.1109/taffc.2017.2736999
11. Grimm, M., Kroschel, K., & Narayanan, S. (2008). The Vera am Mittag German audio-visual emotional speech database. International Conference on Multimedia and Expo, 865-868. doi:10.1109/icme.2008.4607572
12. Livingstone, S. R., & Russo, F. A. (2018). The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLOS ONE, 13(5). doi:10.1371/journal.pone.0196391
13. Lubenets, I., Davidchuk, N., & Amentes, A. (2022) Aniemore. GitHub.
14. Andrew, A. M. (2001). An Introduction to Support Vector Machines and Other Kernel‐based Learning Methods. Kybernetes, 30(1), 103–115. doi:10.1108/k.2001.30.1.103.6
15. Ho, T. K. (1995). Random decision forests. Proceedings of 3rd international conference on document analysis and recognition, 1, 278–282. doi:10.1109/ICDAR.1995.598994
16. Ali, S., Tanweer, S., Khalid, S., & Rao, N. (2021). Mel Frequency Cepstral Coefficient: A Review. ICIDSSD. doi:10.4108/eai.27-2-2020.2303173
17. Zheng, W. Q., Yu, J. S., & Zou, Y. X. (2015). An experimental study of speech emotion recognition based on deep convolutional neural networks. 2015 International Conference on Affective Computing and Intelligent Interaction (ACII). 827-831. doi:10.1109/acii.2015.7344669
18. Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780. doi:10.1162/neco.1997.9.8.1735
19. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. ArXiv (Cornell University). doi.org:10.48550/arXiv.1706.03762
20. Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. ArXiv (Cornell University). doi:10.48550/arXiv.1810.04805
21. Baevski, A., Zhou, H., Mohamed, A., & Auli, M. (2020). wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. ArXiv (Cornell University). doi:10.48550/arXiv.2006.11477
22. Hsu, W.-N., Bolte, B., Tsai, Y.-H. H., Lakhotia, K., Salakhutdinov, R., & Mohamed, A. (2021). HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29, 3451–3460. doi:10.1109/taslp.2021.3122291
23. Chen, S., Wang, C., Chen, Z., Wu, Y., Liu, S., Chen, Z., Li, J., Kanda, N., Yoshioka, T., Xiao, X., Wu, J., Zhou, L., Ren, S., Qian, Y., Qian, Y., Wu, J., Zeng, M., Yu, X., & Wei, F. (2022). WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing. IEEE Journal of Selected Topics in Signal Processing, 16(6), 1505–1518. doi:10.1109/JSTSP.2022.3188113
24. Jang, E., Gu, S., & Poole, B. (2016). Categorical Reparametrization with Gumbel-Softmax. ArXiv (Cornell University). doi:10.48550/arXiv.1611.01144
25. Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. Communications of the ACM, 60(6), 84–90. doi:10.1145/3065386
26. Cho, K., van Merrienboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. ArXiv (Cornell University). doi:10.48550/arXiv.1406.1078
27. Yang, S., Chi, P. H., Chuang, Y. S., Lai, C. I. J., Lakhotia, K., Lin, Y. Y., Liu, A. T., Shi, J., Chang, X., Lin, G. T., Huang, T. H., Tseng, W. C., Lee, K., Liu, D. R., Huang, Z., Dong, S., Li, S. W., Watanabe, S., Mohamed, A., & Lee, H. (2021). SUPERB: Speech processing Universal PERformance Benchmark. ArXiv (Cornell University). doi:10.48550/arXiv.2105.01051
28. Chen, W., Xing, X., Xu, X., Pang, J., & Du, L. (2023). SpeechFormer++: A Hierarchical Efficient Framework for Paralinguistic Speech Processing. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31, 775–788. doi:10.1109/TASLP.2023.323519
Peer Review
Peer reviewers' evaluations remain confidential and are not disclosed to the public. Only external reviews, authorized for publication by the article's author(s), are made public. Typically, these final reviews are conducted after the manuscript's revision. Adhering to our double-blind review policy, the reviewer's identity is kept confidential.
The list of publisher reviewers can be found here.
The article presented for consideration "Automatic classification of emotions in speech: methods and data", proposed for publication in the journal "Litera", is undoubtedly relevant, due to the author's appeal to the study of emotions using technical means. The purpose of the article is to compare the results of frequently used methods based on transformers based on the material of the Russian language. This article discusses the main approaches in the field of automatic recognition of emotions in speech that are currently in use. Section 1 describes the emotion inventories on the basis of which the classification is made. Section 2 is devoted to the collection and processing of data, as well as the currently available corpus of emotional speech. Section 3 provides classification methods that are actively used by researchers in their work, including in this article. Finally, section 4 describes testing and comparing the results of emotion classification obtained by different models. This work was done professionally, in compliance with the basic canons of scientific research. We note the scrupulous work of the author on the selection of practical material and its analysis. The article is groundbreaking, one of the first in Russian linguistics devoted to the study of such topics in the 21st century. The article presents a research methodology, the choice of which is quite adequate to the goals and objectives of the work. The author turns, among other things, to various methods to confirm the hypothesis put forward. To solve research problems, the article used both general scientific methods and linguistic methods. Consideration of the problem of interaction between artificial intelligence and the natural language system is carried out using methods of linguistic observation and description, as well as general philosophical methods of analysis and synthesis. The research was carried out in line with modern scientific approaches, the work consists of an introduction containing the formulation of the problem, the main part, traditionally beginning with a review of theoretical sources and scientific directions, a research and a final one, which presents the conclusions obtained by the author. The bibliography of the article contains 28 sources, among which the works of foreign researchers in a foreign language are presented. We believe that referring to the works of Russian researchers would strengthen the theoretical component of the work. Unfortunately, the article does not contain references to fundamental works such as PhD and doctoral dissertations. In general, it should be noted that the article is written in a simple, understandable language for the reader. Typos, grammatical and stylistic errors have not been identified. The data obtained as a result of the study are presented in the format of graphs and diagrams, which facilitates the reader's perception. The work is innovative, representing the author's vision of solving the issue under consideration. The article will undoubtedly be useful to a wide range of people, philologists, undergraduates and graduate students of specialized universities. The practical significance of the research is determined by the possibility of applying these articles in courses on language theory and computational linguistics. The article "Automatic classification of emotions in speech: methods and data" can be recommended for publication in a scientific journal.
|

 Eng
Eng









